浅谈实时通信的编程模型
Contents
写在前面的话
首先,这是一篇旧文,最早发布于 2016 年 9 月份的公司技术博客上(原文中文章链接已丢失)。
现在回过头来整理这篇文章的时候,我已经离开云巴有一段时间了,想想当初做的东西,现在还是有点唏嘘不已。纯粹的后端云服务相当难做,一个小小的改进可能都需要比较耗心力的打磨,然而市场环境下也不一定愿意买单(做过 2B 业务的同学估计都深有体会)。
后面说的一个分布式 KV 系统,最终做了一个雏形,虽然有许多缺陷,但是勉强可以工作,但后续也没参与到具体的优化工作,想想有点可惜。 类似的系统目前已经出了许多,大多是基于 Raft 算法 + RocksDB 来玩,这是一个相当有意思的领域,有时间再写点东西说说。
概要
有人常问,云巴实时通信系统到底提供了一种怎样的服务,与其他提供推送或 IM 服务的厂商有何本质区别。其实,从技术角度分析,云巴与其它同类厂商都是面向开发者的通信服务,宏观的编程模型都是大同小异,真正差异则聚焦于产品定位,业务模式,基础技术水平等诸多细节上。本文暂不讨论具体产品形态上的差异,着重从技术角度浅谈实时通信的编程模型。
什么是实时通信
「实时」(realtime) 一词在语义层面上隐含着对时间的约束(real-time constraint),在工程上,我们习惯对「需要在一定时间内」 完成的操作称为「实时操作」。通常,实时可细分为 「软实时」(soft realtime),「准实时」(firm realtime)和 「硬实时」(hard realtime)。它们之间的差异,简单来说,就是对无法在指定时间区间内(dealine)完成的事务的容忍程度。维基百科上对这三者有如下解释:
- Hard – missing a deadline is a total system failure.
- Firm – infrequent deadline misses are tolerable, but may degrade the system’s quality of service. The usefulness of a result is zero after its deadline.
- Soft – the usefulness of a result degrades after its deadline, thereby degrading the system’s quality of service.
假如我们把无法按时完成任务(missing a deadline)称为异常事件,那么硬实时系统无法容忍异常事件;准实时系统则可容忍极少量的异常事件,但超过一定数量后系统可用性为 0;软实时系统可容忍异常事件,但是每发生一次异常事件,系统可用性降低。
综上所述,我们可以举例:
-
火星上的无人探测器是硬实时系统,因为一次异常事件就极有可能导致探测器不可用,同理可类推核电站的监控系统,军用无人机系统,远程导弹的导航系统等一系列军工产品;
-
金融交易系统是准实时系统,此类系统可容忍极少数的交易故障,一旦故障次数增加,系统就会陷入崩溃状态;
-
短信 / 手机推送 / 电商购物 等都是软实时系统。对于此类系统,用户都可以容忍异常事件,但是太多的异常事件则会大幅降低系统可用程度,用户体验急剧下滑。
就目前来说,绝大多数互联网产品(甚至可以说是 100%)都是软实时系统。云巴实时通信系统的目标则是要做一个高可用的软实时系统。
一个最简单的实时通信编程模型
在软件工程中,很多复杂的项目其实都可以用一个非常简洁的模型来概括。正如爱因斯坦所说的:「一切都应该尽可能地简单,但不要太简单」(Everything should be made as simple as possible, but not simpler)。虽然这是描述物理世界的经验之谈,但同样适用于计算机领域,将物理世界的关系投射到某种人为语言(物理公式/计算机编程语言),其规律其实都是共通的。
让我们假设这么一个简单的场景:对 10 个客户端发送一条消息。
这个需求其实可以用伪码表示为:
for (i..10) {
send_message(get_socket(i))
}
如果下图所示:
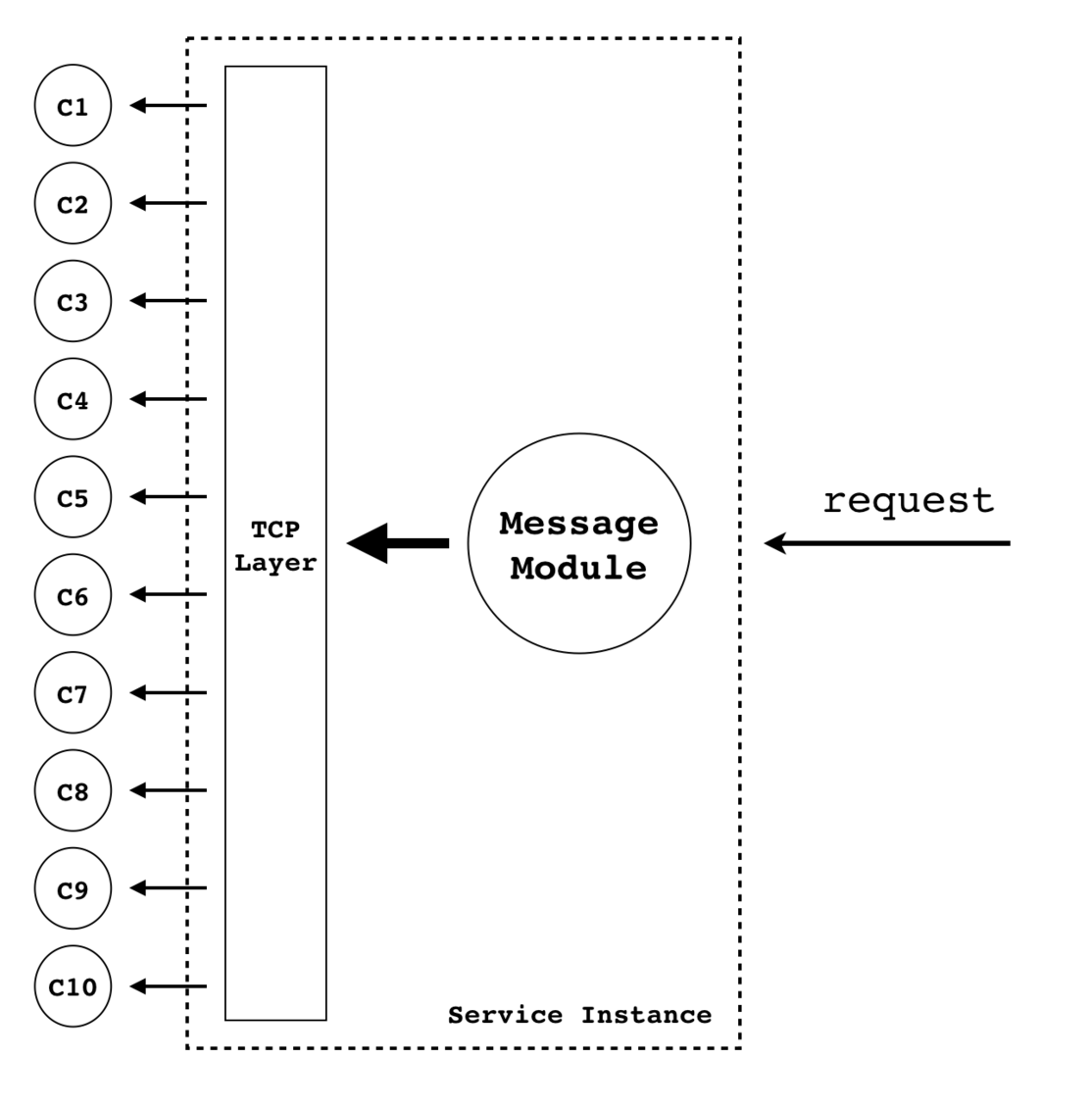
在这个简单的需求下,我们只需要让这 10 个客户端分别跟服务器建立 TCP 连接(本文暂时只讨论 TCP 协议),然后遍历地发送消息即可。显而易见,这是一个 O(N) 复杂度的逻辑。
基于这个简单的模型,我们可以认为一条消息从发出到接收,有以下几个延时:
-
网络延迟 ,一般是一个较为稳定的值,比如从北京到深圳,ping 延迟大约为 40 ms 左右;
-
系统处理延迟,较之网络延迟,该值变化幅度较大,且可能因处理请求数的增加而急剧增大;
云巴实时通信系统以 200 ms 延迟作为总延迟标准,也就是说,假如网络链路是从北京到深圳,除去网络延迟的 40 ms,要想达到 200 ms 的通信时间,系统延迟必须小于 160 ms。
可以想象,当客户端数量达到一定数量级(比如百万级别)时,以上系统模型的实时性将面临极其严峻的考验。
分而治之
在海量用户下保持稳定的实时性,其实很多时候就只有一个手段:分而治之。
图 1 表示的是单机处理情况。当单机的处理能力,带宽都无法应对客户端数量急剧增加的时候,我们就必须将线路进行分割。而且图 1 只体现了推送的意图(单向),但通信往往是一个双向的概念,综上,我们将 图 1 改成下面的 图 2:
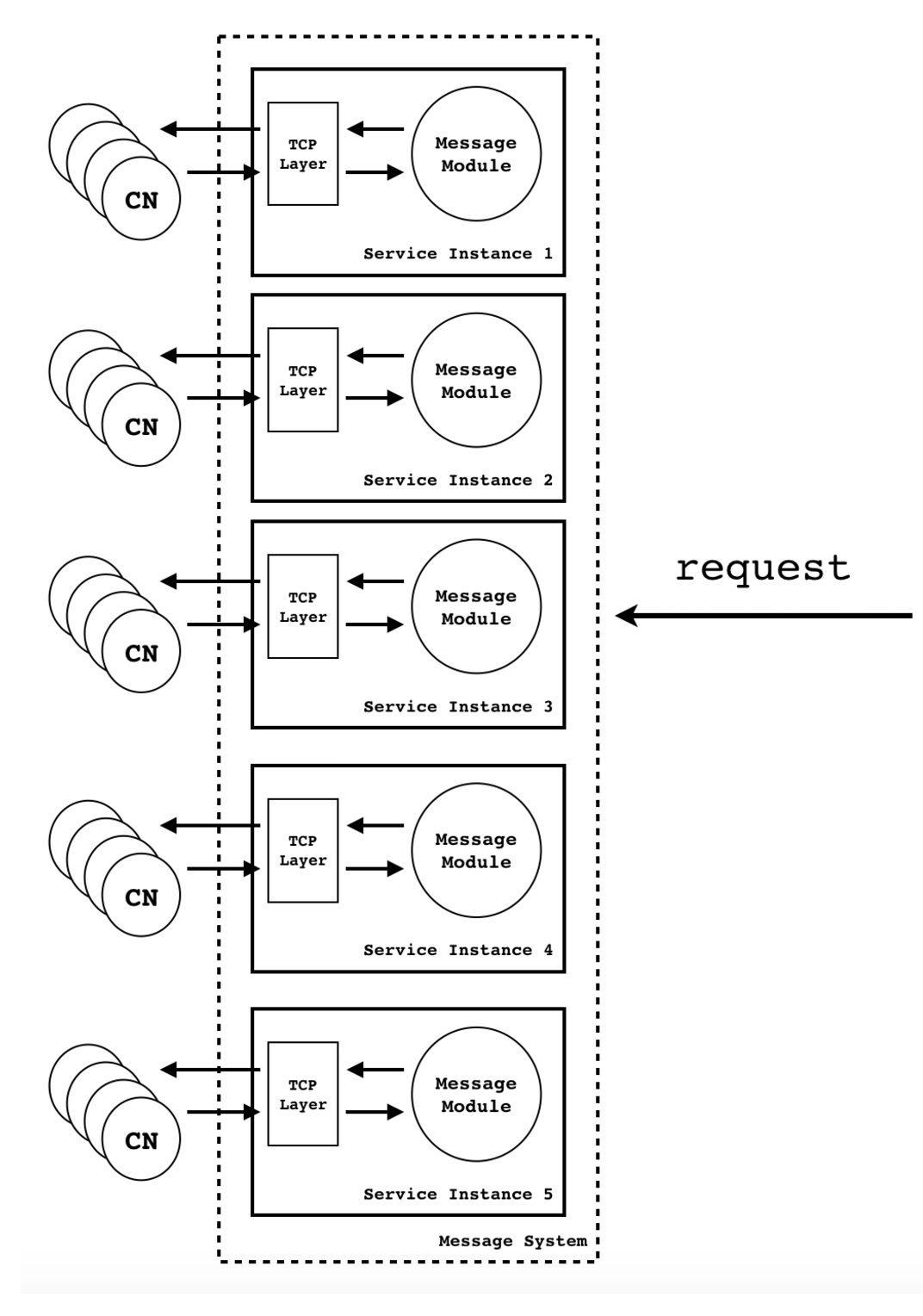
这样每台机器就可以处理符合其当前水位(watermark)的连接。
在现实开发中,我们可能不仅仅满足于一个如此简单的消息系统,我们可能想要有离线消息,数据统计,数据缓存,限流等一系列操作,所以我们还可以再优化一下架构:
-
将整体架构划分成业务逻辑层和数据存储层;
-
数据存储层又可以根据存储数据的不同来进行进一步的划分;
-
前端可以单独划分一个网络接入层;
-
数据包的流向可以用 MQ 来串联;
这样我们可以得到以下的图 3:
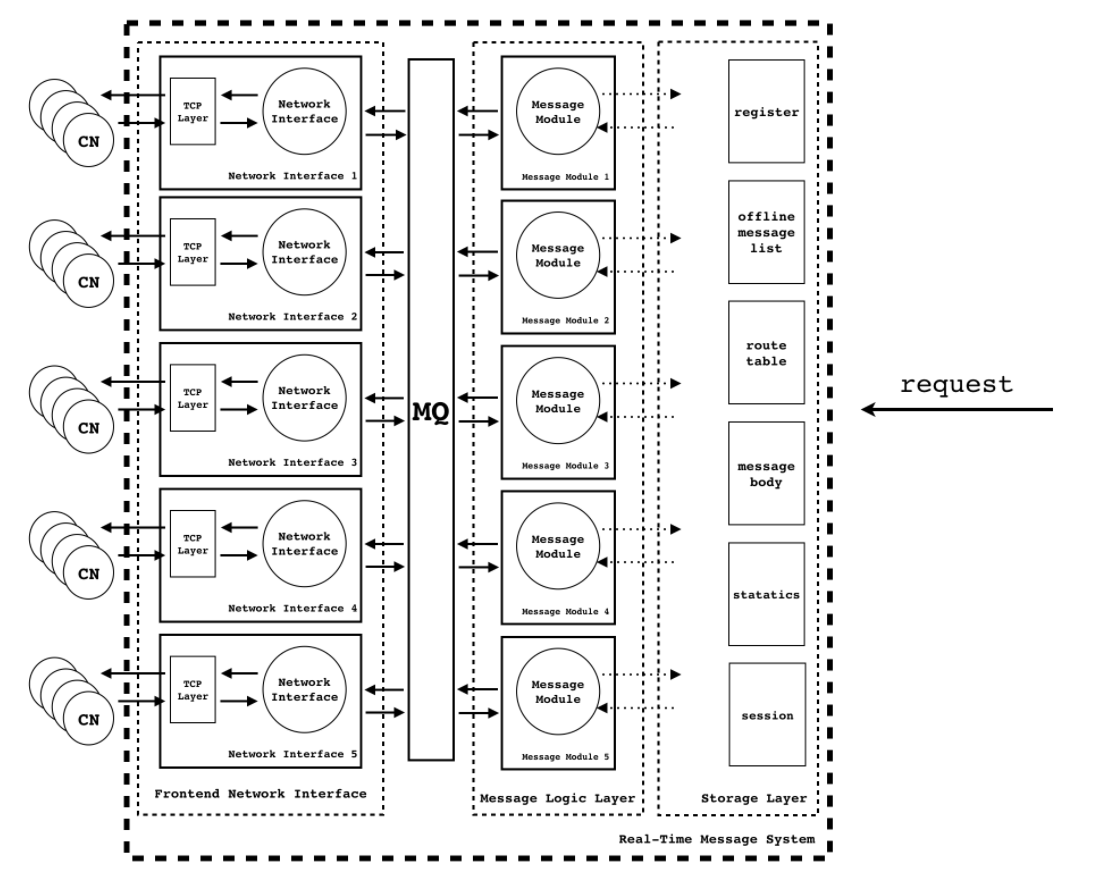
在这个模型中,网络接入层和消息业务逻辑层整体上应该是一个 stateless 的模块,可以较为轻松地做横行扩展。存储层作为一个有状态的模块,想要做到横行扩展是一件很不容易的事情。如果撇开这点来看,至此,这个模型理论上在应对海量用户的场景下应该是有效的。
通信协议和技术栈的选择
做一个消息系统,不可避免地要涉及到对通信协议的选择。我们在对通信协议的选择上,遵循以下几个原则:
-
协议尽可能精简轻量,因为在系统设计之初我们就考虑了对物联网的支持,省电,节约流量都是目标之一;
-
通用性好,扩展性强,方便后期做特性开发;
-
协议在业界被广泛认可,且尽可能多的有不同语言的开源实现,以方便不同技术栈的客户做集成;
综上,我们没有重新自定义一份通信协议,而是选择了 MQTT。从很多角度来看,MQTT 非常适合做消息总线的通信协议,而且协议栈也足够轻巧和易于实现。云巴实时消息系统传输的消息体积较小(一般小于 4 KB),比如控制信号,普通聊天信息等。就这点上,针对物联网设计的 MQTT 有着天然的优势。后面,在不断的研究中我们又发现,MQTT 其实不仅仅适用于物联网场景,在很多要求低延迟高稳定性的非物联网场景也同样适用(比如推送,IM,直播弹幕等)。
从前面几个章节我们看到,云巴消息系统是一个典型的 IO 密集型系统。在出于开发效率和稳定的考虑下,我们选了 Erlang/OTP 作为主力开发语言。Erlang/OTP 作为一门小众开发语言(无论是国内还是国际),在应付这类 IO 密集型系统上,有着得天独厚的优势(可参考 RabbitMQ 这个基于 Erlang/OTP 的著名开源项目):
-
基于 actor 的进程创建模型,可以为每个数据包创建一个 Erlang 处理进程,充分利用多核;
-
OTP 的开发框架抽象了分布式开发的许多细节,使得开发者在很小的心智负担下就能轻松快速地开发出功能原型;
-
Erlang/OTP 充分运用了容错思想,应对异常不是防,而是容,很多时候我们写出一些安全逻辑上有漏洞的代码,在 Erlang/OTP 上居然也能工作得好好的;
随着不断深入地使用 Erlang/OTP, 其性能问题也渐渐凸显出来。我们发现,当客户端请求量增加的时候,用 Erlang/OTP 写出的模块轻而易举地就可以将 CPU 跑满,从而让当前实例超负荷运转。很多时候出于成本上的考量,我们无法选择更多核数的机器来提升 Erlang 虚拟机运行的性能(此点未明确验证过),所以只好选择适度增加服务处理实例来缓解压力。
不过,通过对业务模块更细粒度的划分,我们可以将一些核心的小模块用 C/C++ 语言改写,在一定范围的复杂度内,可以有效提升整体处理性能。这也是我们接下来优化核心系统的思路之一。
MQTT 的 Pub/Sub 模型与高可用 KV 存储
MQTT 协议采用的是 Pub/Sub 的编程模型。其中有三个比较关键的动作:publish,subscribe 和 unsubsribe。通过前面几个章节的讨论,我们又可以得到这么一个场景:
假如存在一个订阅量巨大的 topic(百万级),如何在单次 publish 中保证实时性 ?
其实,解决思路跟之前的场景是一致的:分而治之。我们必须通过某种策略对 topic 进行分片,然后在将分片分发到不同的 publish 模块上进行处理。在一定算法复杂度下,这个问题理论是可以被有效解决的。于是,topic 的分片策略就成了高性能 publish 的关键。其实,如果想采用 MQTT 做海量的消息系统,订阅关系的管理一定是无法绕开的问题。它主要有以下几个设计难点:
-
如果采用 KV 方式存储,如何设计数据结构 ?同上,我们要怎样去设计一种高效的 topic 分片存储策略;
-
订阅关系的管理是 MQTT 的核心模块,假如这个存储模块实效,就必定会导致消息通信失败,从而让客户端收不到消息,这就必须要求这个模块一定是高可用的,这就意味着我们必须构建一个高可用的 KV 存储集群,该集群要能容忍一定层度的节点实效;
-
冷热 topic 要有一定的淘汰机制,要有一定策略将不活跃的 topic 定期淘汰到磁盘以节约内存容量;
-
KV 存储集群要有高效的动态扩容机制;
在很长一段时间的实践中,我们采用过好几种 KV 存储的集群方案,踩了不少坑,最后还是决定自己造轮子来开发一个高可用的 KV 存储模块。不过这又是一个很大的话题,我们将在后续博客中具体阐述我们的做法。
缺陷与不足
在团队发展初期,由于人力和时间等种种因素,我们把业务逻辑模块开发成了一个巨大的单体架构的应用。在团队规模较小的情况下,单体架构的应用确实较好维护和开发,当随着新人的加入,单体架构严重制约着特性开发和性能优化。从架构层面,合理地划分更细粒度的模块,在性能和可维护性上采用微服务(microservice)设计模式,成了我们未来优化系统的方向之一。
总结
软件工程上有「没有银弹」(No Silver Bullet)这条金科玉律,用户选择云服务商亦是如此,绝对没有完美的第三方云服务商,每一家都可能存在明显的优点和缺陷。用户必须从自己应用场景和痛点出发,选择合适的后端服务。云巴目前会在自己产品的核心竞争力上持续发力,精打细磨,吸取行业内的高效实践,打造出更加优秀的高可用实时通信系统。