Rust 的 Pin 机制
Contents
背景
我相信大多数人在学习 Rust 异步编程时都会被 Future trait 中的 Pin 指针感到困惑:
|
|
特别是搜索了一圈文档之后,更会对这个 Pin 一头雾水,彷佛自己也被 Pin 住了一样。本文将尝试逐步一点点去解释 Pin 的来龙去脉,希望能够提供更容易懂的知识结构。
快速体验 Pin
我们可以在只了解以下几个基本事实的基础上快速体验 Pin,从而从直觉上了解它的作用。
-
Pin<P>是一个泛型数据结构,其中包裹的P必须是指针,或者更准确地来说:必须是实现了 Deref trait 的对象。我们可以将Pin<P>理解为Pin<P<T>>,其中T是最原始的数据类型; -
Pin<P<T>>是指针,对其解引用将获取*P中的类型,即T,常见的P<T>可以是Box<T>、&T、&mut T等; -
给定
Pin<P<T>>类型的数据,只要T不满足 Unpin trait,则 Safe Rust(即不使用unsafe{}块)下无法获得&mut T和T。换言之,要想Pin有其效果,则T必须不满足 Unpin trait;
在理解了以上几条,我们来简单快速尝试一下 Pin:
|
|
如上例子所示:
-
我们先创建数据在堆上的
Box<Foo>指针,然后再基于Box<Foo>创建 Pin 指针,上面这两句代码也可以简化为用Box::pin()函数:1let pin_foo: Pin<Box<Foo>> = Box::pin(Foo::new())二者是等价的。
-
&*pin_foo相当于获取堆上Foo数据的不可变引用。此处必须使用引用。如果直接使用*pin_foo,相当于我们通过解引用获取所有权,这在 borrow checker 中是不可行的,将触发 E0507 错误; -
println!接收的就是&T类型参数,所以我们最终可以如预期获得相应的打印:1Foo { x: 0, y: 1 }
从逻辑上来看,这段代码在实际堆栈上如下所示:
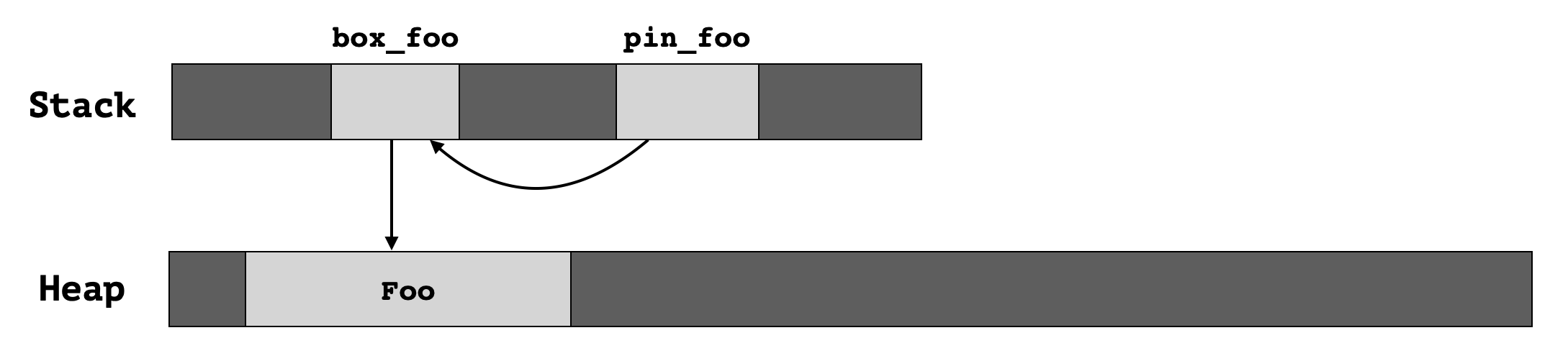
我们此时再想想事实 1,即 Pin<P> 中 P 必须是指针,比如上面例子中的 Box<Foo>。如果我随便传入一个非指针值呢?比如:
|
|
聪明的 Rust 编译器立即就发现问题:
|
|
整型的 2 并没有实现 Deref trait,不被认为是一个指针。
此时让我们基于这个简单的例子体验一下第 3 个基本事实,即只要 T 不满足 Unpin trait,则 Pin<P<T>> 无法在 Safe Rust 下获得 &mut T 。
Unpin trait 是一个特殊的 marker trait(可以理解为类似于 Send 或者 Sync trait),它不需要实现什么具体的方法,仅仅只是一个标记,Rust 默认给所有类型都自动实现了 Unpin trait,也就是说,对于原生类型或者自定义类型,编译器都自动为其实现了 Unpin trait,也就是说,此时的 Pin<P<T>> 可以获取到 &mut T,让我们试一下:
|
|
编译没有问题(可以使用 cargo check),这说明自定义的 Foo{} 确实不满足基本事实 3。
我们如何显式地不让编译器为我们实现 Unpin trait ? 最简单且通用的方式就是使用 PhantomPinned。PhantomPinned 是一个空的结构体,是一个 marker type。只要类型中含有这个 marker 成员,则表示对应类型默认不要实现 Unpin trait,此时我们可以将代码改成:
|
|
发现此时无法编译:
|
|
为什么会出现这个错误 ?其实还得看 Pin::new() 的签名定义:
|
|
上面的泛型约束 P: Deref<Target: Unpin> 说明了 Pin::new() 必须是:
Pin<P>中P需满足 Deref trait;Pin<P>中P所包裹的Target需满足 Unpin trait;
很显然,当 Foo{} 被显式不实现 Unpin trait 时,已经无法使用 Pin::new()。
这时候,要为不实现 Unpin trait 的类型构造 Pin,必须使用 unsafe 的 Pin::new_unchecked(),即:
|
|
此时我们再次编译,会发现有如下错误:
|
|
我们暂且不要去理解这个错误,可以认为是编译器阻止我们创建 &mut Foo 类型变量,即基本事实 3 所说的内容。当我们把 mut 关键字去掉时,如下:
|
|
则编译通过,说明 &Foo 类型的变量还是可以正常创建。
至此,我们深呼一口气,对 Pin 的初体验暂且告一段落。
Pin 想解决的问题
核心能力
我们可以从 Pin 模块的文档上提炼出这么几句话:
…
…
Pin<P>does not let clients actually obtain aBox<T>or&mut Tto pinned data……
Pin<P>prevents certain values (pointed to by pointers wrapped inPin<P>) from being moved by making it impossible to call methods that require&mut Ton them (likemem::swap).…
其实,我们的体验篇的基本事实 3 就很好的概括了 Pin 的核心能力:给定 Pin<P<T>> 类型的数据,只要 T 不满足 Unpin trait,则 Safe Rust 下无法获得 &mut T 和 T,从而让 T 不能被 move。
这样一来,只要用 Pin<P<T>> 类型的数据,Safe Rust 下也无法使用依赖于 &mut T 的 API(编译器会阻止)。
为什么 Rust 要引入 Pin 机制去阻止用户获取 &mut T 和 T?很大原因是为了解决自引用结构体带来的不安全问题。我们接下来就来介绍什么是自引用数据结构及其存在的问题。
自引用结构体
自引用结构体(self-referential struct)非常容易理解:就是结构体成员引用(持有指针)了当前结构体的其他成员。举个例子,假如我们有一个数据架构 SelfReferenceFoo(注意:结构体内使用引用需要显式用上生命期注解):
|
|
其中:data 是一个 String 类型的变量,而 data_ref 是一个初始化时指向其成员 data 的一个引用变量。让我们来看看是否可以成功初始化:
|
|
编译时发现了错误:
|
|
很明显,s 的所有权已经 move 给了 foo.data,则 s 已经失去了对数据的所有权,所以 &s 是一个无效的引用,不能赋给 data_ref。
那我们是不是可以绕一下 ?由于 Rust 的引用初始化必须被赋值,那么我们是不是可以:先初始化一个 mut SelfReferenceFoo,data_ref 成员先暂时用一个临时的 String 引用变量代替,待 mut SelfReferenceFoo 变量创建完了再将其修改成真实的 data 引用。比如下面这种做法:
|
|
编译运行成功!
|
|
而且最后输出的内存地址也表明 foo.data_ref 确实指向了 foo.data 所在的地址。此时逻辑上内存 layout 如下所示:

由于 String 类型的字符串数据是存放在堆上,所以 data 内部的数据结构将指向堆上的一个地址。
看起来 Rust 编译器并没有阻止我们使用自引用结构体嘛。但是,如果我们想将 foo.data 修改成其他值:
|
|
此时编译器将会报错:
|
|
编译器提示我们 foo.data 已经被 borrowed,此时无法修改 foo.data,否则其先前的借出值 foo.data_ref 将可能会成一个悬垂指针。虽然我们持有一个 mutable 的 SelfReferenceFoo,但却无法修改 data 字段(data_ref 可以被修改)。这在实际使用中是没有价值的。
上面几个简单的尝试告诉我们,对于自引用结构体,其初始化和使用都受到了 Rust borrow checker 的层层限制,我们几乎没法以符合直觉的方式来安全使用自引用结构体。
使用自引用结构体存在的问题
为了进一步绕开 Rust borrow checker 的检查,从而更好地说明自引用结构体存在的问题,我们不得不使用 Rust 中的裸指针。我们将 SelfReferenceFoo 修改为:
|
|
将 data_ref 改成对 String 的裸指针 *const String。裸指针的初始化可以用 std::ptr::null() 将其设置成空指针,比如我们为 SelfReferenceFoo 构造了以下两个函数:
|
|
参考之前的实验,我们可以创建一个变量并输出 data 和 data_ref 的内存地址:
|
|
这段代码与之前的实验的输出是类似的。当然,也可以对 foo.data 重新赋值(用裸指针等于绕开了 borrow checker):
|
|
我们可以在 Safe Rust 里安全地创建一个裸指针,但是解引用裸指针必须在 unsafe{} 中。比如我们需要用如下方式才能获得对 data 的引用:
|
|
其中 *foo.data_ref 解引用裸指针获得 String 变量,再用 & 获得 &String 类型的引用。
综上,我们可以增加以下两个方法来分别打印 data 和 data_ref 的数据和地址:
|
|
使用自引用结构体最大的问题就是:当对应结构体变量发生 move 动作时,结构体变量内的自引用指针将处于一种不安全的状态。
比如下面这段简单的代码:
|
|
代码将打印出:
|
|
我们很明显可以看到:
new_foo中data字段的内存地址已经发生了改变,从原来的0x7ffee62ec230改变到0x7ffee62ec298;new_foo中的data_ref依然指向旧的foo.data,此时new_foo中的data和data_ref将出现不一致。因为旧的foo的数据还未被回收覆盖,所以此时println()操作还可以正常打印;
在 Rust 中,move 动作从语义上是所有权发生了改变,但是底层实现是执行了变量的 shallow copy,同时让前一个变量不可用(所有权转移到新变量上),上述代码执行完 move 之后的内存 layout 如下图所示:

我们要特别注意上图中的红色线:data_ref 指向了一个即将被内存回收的区域,因此处于一种不安全的状态。将 foo move 到 new_foo,其实也可以理解成是一个 memcpy 的过程,比如文档中提及调用 std::mem::swap() 也是可让自引用结构体处于不安全状态的一种典型的 API。
用 Pin 来解决问题
那么我们如何利用 Pin 来解决问题 ?根据我们之前的经验,我们得先显式让 SelfReferenceFoo 不实现 Unpin trait,即增加 PhantomPinned 类型的 _marker:
|
|
然后我们将 new() 改为:
|
|
我们使用 Pin,是想将 mut &SelfReferenceFoo 包裹在 Pin 中,即最终用户只能使用 Pin<mut &SelfReferenceFoo>。结合我们之前的经验,我们可以这样创建 Pin<mut &SelfReferenceFoo> 类型变量:
|
|
由于用户只能使用 Pin<mut &SelfReferenceFoo> ,我们同样要调整一下 set_data_ref() 的逻辑:
|
|
一共三句代码,我们逐条分析:
-
由于不满足 Unpin trait 的 Pin 也实现了 Deref trait(注意:该状态下的 Pin 没有实现 DerefMut trait,所以无法获取
&mut T),所以我们可以直接获得data指针,其实也可以写成:1let data_ref: *const String = &pinned_data.as_ref().get_ref().data as *const String;as_ref()是获得Pin<&SelfReferenceFoo>,而get_ref()是获得&SelfReferenceFoo。
-
在
Pin<P<T>>中获取&mut T方式(T 不满足 Unpin trait )就是调用 unsafe 的get_unchecked_mut()。这句代码是我们这个例子中唯一使用到&mut T的地方,目的是为了修改data_ref的值,将其指向data。
同理,我们将 print_data() 和 print_data_ref() 修改为:
|
|
此时我们可以这样使用新的 SelfReferenceFoo:
|
|
那么我们还可以对 SelfReferenceFoo 执行 move 动作吗 ?回答是:在 Safe Rust 中我们没有办法获得 Pin<&mut SelfReferenceFoo> 中的 SelfReferenceFoo 变量的所有权,所以我们无法执行 move。而且在 Safe Rust 中我们也无法获得 &mut SelfReferenceFoo,从而也无法调用 std::men:swap() 。所以顾名思义,SelfReferenceFoo 变量的区域就相当于被 Pin 住一样,只能读,无法 move 和获得可变引用。而如果我们 move Pin<&mut SelfReferenceFoo>,并不影响 SelfReferenceFoo 变量。
综上,Pin 机制就是提供了一种方式,包裹住自引用结构体的指针,从而从编译器层面避免自引用结构体被 move。如果非得 move,则用户自己使用 unsafe API,自己负责其安全性。
Future 中存在的自引用结构体
让我们来重新回过头来看 Future trait 的定义:
|
|
现在是不是很好理解呢 ?poll() 中的 Pin<&mut Self> 表示:实现 Future trait 的类型有可能是一个自引用结构体,为了安全性,我们需要将其用 Pin 包裹起来。
为什么实现 Future trait 的类型有可能是一个自引用结构体 ?那这必须从 Rust 的异步机制说起。不同于 Go 的基于 stack 的 goroutine 机制,Rust 利用 async {} 关键字将可被异步化的逻辑封装成一个 Future,而多个 Future 交给各种不同的 Executor 采取不同的调度机制来执行(比如 future-rs、tokio、async-std 等等)。在编译器的背后,每一个 async 部分的逻辑都将被编译成一个个实现了 Future trait 的结构体,而且结构体内部维护着一个状态机,状态机内部的每一个状态则是 .await 点。这样的结构体也可以理解为是一个 coroutine 或者 task。
如果一个 Future 内部有多个 .await,而遇到 .await 则说明当前操作需要等一等(很多时候是 IO 操作),可以让当前 CPU 去干点其他事。此时,.await 点相当于让出(Yield)CPU,让 Executor 去执行另外的 Future。为了让这个状态机可以恢复 .await 前后的状态,编译器需要将相应的变量保存起来,形成一个结构体,且这个结构体需要实现 Future trait。在这个过程中,由于这个结构体不仅要保存上一个状态中的一些变量,而且有可能当前状态的 Future 中依赖于上一个状态生成的变量,这就将产生自引用结构体。Rust 这种实现 coroutine 的方式称之为 stackless coroutines,区别于 Go 的 stackful coroutines(即 goroutine)。
因此,为了保证这个 coroutine 生成过程的安全性,我们用 Pin 将实现 Future trait 的潜在自引用结构体给钉住。
Pin 的核心 API
几个关键的 API
备注:!Unpin 表示不实现 Unpin trait,可参考最后一节的内容。
参考文档的分类,我们可以重点关注 Pin 模块中的这几个 API(下面的 API 均在 std::pin::Pin 这个模块中):
-
构造
Pin<P<T>>-
如果 T 是 Unpin,可直接使用安全的
new(),比如:1 2let box_foo: Box<Foo> = Box::new(Foo::new()); let pin_foo: Pin<Box<Foo>> = Pin::new(box_foo); -
如果 T 是 !Unpin,需使用不安全的
new_unchecked(),比如:1 2let box_foo: Box<Foo> = Box::new(Foo::new()); let pin_foo: Pin<Box<Foo>> = unsafe { Pin::new_unchecked(box_foo) };
或者是将变量用
Box::pin()Pin 在堆上,此时无需区分使用哪一个 API。 -
-
获取
&Tget_ref():获取&T,适用于 T 是 Unpin 和 !Unpin 安全 API;get_muf():获取&mut T,适用于 T 是 Unpin 的安全 API。对于 T 是 Unpin 的场景,获取&mut T是一个安全操作;get_unchecked_mut():获取&mut T,适用于 T 是 !Unpin 的不安全 API;
-
获取
Pinto_inner():输入Pin<P>变量,获得P,此时将消耗Pin<P>。适用于 T 是 Unpin 的安全 API;into_inner_unchecked():输入Pin<P>变量,获得P,此时将消耗Pin<P>。适用于 T 是 !Unpin 的不安全 API;
-
转换
Pin类型
另一种阻止编译器不实现 Unpin 的方法
除了显式在结构体内加入 PhantomPinned marker 变量阻止编译器实现 Unpin trait,Rust 还提供了 negative_impls 方式来直接声明不让对于结构体实现 Unpin trait。如下所示:
|
|
其中:
#![feature(negative_impls)]:告诉编译器需要 negative_impls 这个 feature;impl !Unpin for Foo {}:!Unpin表示不实现 Unpin trait;
由于 negative_impls 特性目前还没有加入在主干上,我们需要用到 nightly 特性,上面的代码可以用如下方式进行编译:
|
|