为什么不应该在 DBMS 中使用 MMAP | 读读论文
Contents
论文地址
今天阅读的是著名的 Andrew Pavlo 和他学生合作的一篇发表于 CIDR 2022 的 Paper,名为:Are You Sure You Want to Use MMAP in Your Database Management System? 。
被 MMAP 引诱的开发者
MMAP 是内核提供的一种可以将持久化存储上的文件直接映射到用户态地址空间的一种特性。用户可以直接使用指针操作文件内容,就像整个文件整个驻留在内存中一样。内核将会帮用户管理对应的页面,比如延迟加载页面、将脏页自动刷入持久化存储、基于内存压力驱逐页面等等。因此,对于 DBMS 开发者而言,他们可以直接使用 MMAP 而无需自己从头利用 read/write 等这类基本系统调用重新实现一个 Buffer Pool。论文用了一段很有意思的话来描述:
…
mmap’s perceived ease of use has seduced database management system (DBMS) developers for decades as a viable alternative to implementing a buffer pool.
…
确实,采用 MMAP 来实现一个数据库会大幅降低整体工程量,一直 “引诱” 着无数数据库开发者。著名的 MongoDB 和 InfluxDB,早期的引擎都是采用 MMAP 来实现。
但是,将管理页面的事情交给内核就意味着让渡了很大部分的数据控制权。为了实现数据库的一些关键特性,开发者不得不做一些适配 MMAP 特性的复杂逻辑来保证其正确性和性能。本文分析了 MMAP 四宗罪,最后得出的结论是:在大多数场景,永远不要用 MMAP 来实现数据库。
MMAP 的原理
简化过程
MMAP 本质上将二级存储(比如硬盘)上的文件的物理页直接映射于 1 个或者多个进程的用户态虚拟地址空间,并由内核来管理页面。这样一来,DBMS 便可以无需用户态的 Buffer Pool 来负责数据的移动。
在具体的实现上,MMAP 是一个 mmap() 系统调用,其整体简化过程如下图所示(假设数据库只有一个 cidr.db 文件):
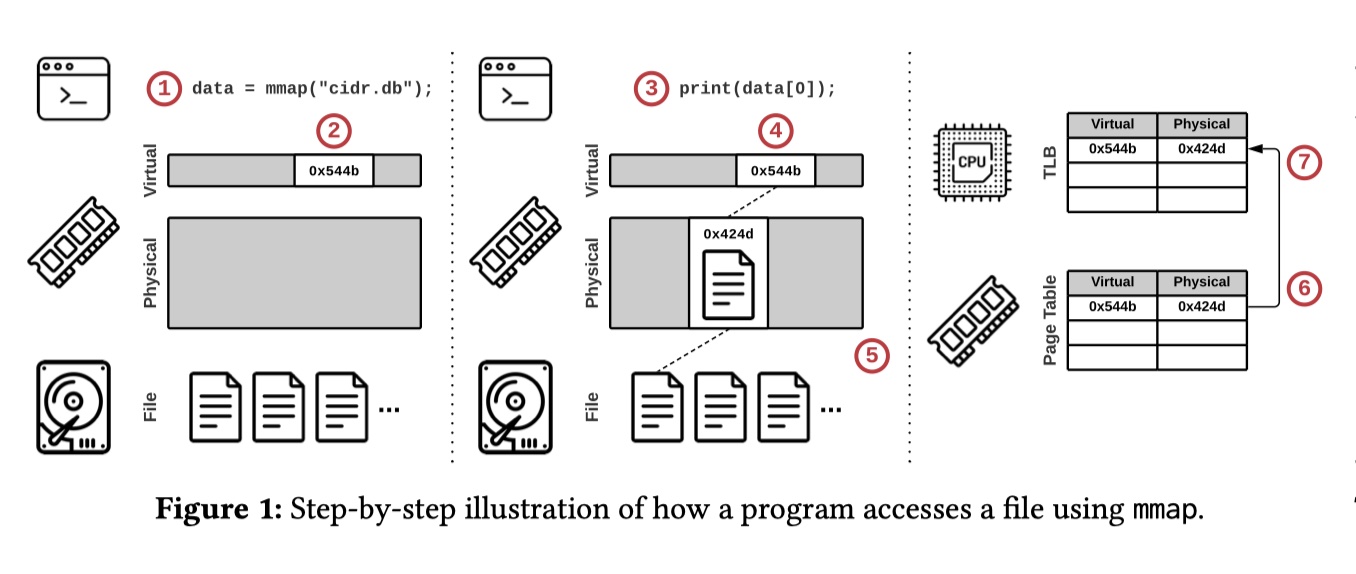
- 使用
mmap()系统调用映射文件并获得其指向进程虚拟地址空间的数据指针; - 内核保留了进程这部分虚拟地址空间但仍未加载任何文件(lazy loading);
- 进程利用 1 获得的数据指针访问了文件内容;
- 内核尝试访问这部分虚拟地址空间;
- 由于这部分虚拟地址空间并不存在有效的页面映射,因此内核将触发一个 page fault 来从二级存储中加载对应区域的文件到物理内存页;
- 内核创建一个 entry,记录虚拟地址空间地址到新的物理页地址之间的映射;
- 为了加速访问,6 中的 entry 会被缓存于 CPU 的 TLB 上,之后的访问会先访问 TLB。一般来说,CPU 每个核上都有自己的 TLB;
TLB Shutdown
当用户访问其他页面时,内核会对应文件页面加载进内存。如果此时内核页缓存满了,将触发内核驱逐页面。当页面被驱逐走时,内核同时需要删除 TLB 上的相应 entry,即 Flush TLB。Flush 本地核的 TLB 是一件相对简单的事情,但为了确保其他核上不会访问到过期的页面,内核不得不(目前 CPU 没有其他额外的廉价机制)触发昂贵的 inter-processor interrupt 来 Flush 所有的 TLB,这就是 TLB Shutdown。TLB Shutdown 是一个影响 MMAP 性能的关键因素。
POSIX API
以下这些其实都是系统调用,我们可以在 linux-system-calls 进行查阅。
-
mmap():此调用将文件映射到虚拟进程空间。这里有两个常用的的 flag:MAP_SHARED:内核最终会将进程对文件的修改写回底层文件。这意味着,如果有多个进程打开同一个文件,这些进程将可以同时看到文件的修改。因此,MMAP 也可以被作为一种高效的 IPC;MAP_PRIVATE:进程对页面的修改会通过 copy-on-write 创建一个仅对当前进程可见的私有映射,且其修改不会持久化到底层文件中;
内核还提供了:
munmap():此调用来解除内存映射;mermap():此调用用于调整现有内存映射的大小或位置;
-
madvise():此调用向内核提出那个有关预期数据访问模式的 hint,在 Linux 上:MADV_NORMAL:默认行为。当页面被访问时,内核将获取被访问的页面以及前 15 个页面和后 16 个页面。也就是说,对于 4KB 大小的页面,尽管调用者只请求了单页,但MADV_NORMAL将会从二级存储中读取 128KB((15+1+16)*4)大小的数据,这种预取可能会对 DBMS 的性能造成影响;MADV_RANDOM:告诉内核内存是随机访问,只读必要的页面,比较适合 OLTP 负载;MADV_SEQUENTIAL:告诉内核内存是顺序访问,会增加预读量,比较适合 OLAP 负载;
-
mlock():此调用允许页面 pin 在内存中,确保内核不会将其驱逐。但根据 POSIX 标准以及具体的 Linux 实现,内核会在任何时候将脏页写回文件,尽管页面被 pin 住,因此 DBMS 不能使用mlock()来保证脏页永远不会被写入二级存储,这对实现事务上将带来很大影响。内核还提供了munlock()来解除 pin 状态; -
msync():显式地将指定内存区域 flush 到二级存储中。如果没有msync(),DBMS 没有其他方式确保变更已经持久化到文件上;
MMAP 四宗罪
#1: 复杂的 Transaction Safety
由于让内核管理脏页的写入,内核可以不管写入事务是否已提交就随时将脏页面刷新到二级存储。DBMS 没有任何方式阻止这些刷新,也无法在刷新发生的时候收到通知。因此,DBMS 不得不采用一些复杂的协议来确保 transaction safety。论文总结了 3 种具体的方式(基本都是 COW,即先写到其他地方然后再传播更新):
-
OS Copy-On-Write
这是 MongoDB MMAPv1 引擎采用的方式。
使用
mmap()创建文件的两个副本,同时指向同样的物理页,第一个为 Primary Copy,第二个则作为 Private Workspace(用MAP_PRIVATE打开)。- Private Workspace 用于接收事务更新,此时页面的修改对 Primary Copy 不可见。为确保其持久化,将采用 WAL 来记录更改;
- 当事务提交时,DBMS 用 WAL 将对应的记录持久化到二级存储中,并用单独的后台进程将提交的更改应用于 Primary Copy 中;
这种做法会有两个主要问题:
- DBMS 必须确保已提交的事务的最新更新已经传播到 Primary Copy,然后才能允许冲突事务允许,这需要额外的元数据跟踪;
- 随着更多事务的发生,Private Workspace 的内存使用会持续增长,最终 DBMS 在内存个中可能会有数据库的两个副本。为了解决这个问题,DBMS 可以定期使用
mremap()来缩小 Private Workspace。然而,DBMS 必须再次确保所有待处理的更新已传播到主副本,然后才能销毁私有工作区。此外,为了避免在mremap()期间丢失更新,DBMS 需要阻止待处理的更改,直到mremap()完成;
-
User Space Copy-On-Write
SQLite 采用这种办法的某种变种。
手动将受影响的页面从 mmap 映射的内存区域中复制到用户空间单独维护的缓冲区。当进行事务时,DBMS 仅对副本更改并创建相应的 WAL。随着事务的提交,DBMS 可以将 WAL 持久化并将修改过的页面复制回 mmap 所映射的内存中。
-
Shadow Paging
DBMS 维护由 mmap 支持的数据库的主副本和影子副本。当进行更新时,DBMS 首先将受影响的页面从主副本复制到影子副本,然后在影子副本上应用更改。接着利用
msync()将修改过的影子副本页面刷新到二级存储中并更新指针将影子副本安装为主副本,原始的主副本则变成新的影子副本。
#2: I/O 卡顿
MMAP 原生并不支持异步读取,所以使用 MMAP 时,当读取不存在于内存中的页面时将触发阻塞性的 page fault。由于 MMAP 有可能把某个页面逐出到了二级存储上,当访问者访问到不处于内存中的页面时则将触发 page fault,这就将导致 I/O 卡顿(I/O Stalls)。
DBMS 开发者可以用 mlock() 来锁定不久后将会再次访问的页面,但内核通常会限制单个进程可以锁定的内存量,因为锁定太多页面可能会造成内存压力。除此之外,DBMS 还要额外地跟踪不再使用页面以便 munlock()。另一种方式是用 madvise() 来针对某些数据访问模式来预取页面,但这并不是很可靠的方式,因为内核可以忽略这些 hint。
除此之外,开发者还可以用额外的线程来预取页面,这样 I/O 卡顿将不会发生在主线程,但这增加了设计复杂度。
#3: 复杂的错误处理
为保证数据完整性,DBMS 通常维护页面的 checksum。由于 MMAP 有可能在某个时刻将某个页面逐出到了二级存储上,因此当 DBMS 每次访问页面时,为保证其数据完整性,都必须校验 checksum(因为有可能持久化存储或其他过程中出现问题)。大多数 DBMS 都是采用内存不安全的语言进行编写,这意味着内存中的页面很有可能被一些指针错误破坏。而由于 MMAP 会随时刷脏页,这就意味着损坏的页面可能会被存储到二级存储上。
当使用 MMAP 时,访问映射区间的一些内存错误会以 SIGBUS 信号的形式透出,这就意味着 DBMS 还需要实现繁琐的信号处理器,这就很难优雅处理 I/O 错误。
#4: 性能问题
与前面几个问题比起来,MMAP 最显著的问题其实是性能,而这个问题除了重新设计内核之外别无解法。
传统观点看来 MMAP 将提升性能,因为:
-
MMAP 建立起了用户态地址空间与物理页之间的映射,很多读写都不需要显式走系统调用,这将减少很多系统调用(比如
read和write); -
将数据从物理介质读取之后,MMAP 避免了从内核缓冲区拷贝到用户缓冲区的过程;
实际上,论文作者做了几个实验表明现代的的 NVMe 存储上并非如此。主要是:
-
页表竞争
多线程场景下,频繁的页面替换需要内核更新页表,这无疑将带来锁竞争;
-
内核的页表的驱逐是单进程
当内核的页缓存被用满时,任何对新数据的访问都需要内核驱逐旧的页面,为新的数据腾出空间。Linux 使用的后台进程
kswapd是一个单进程,高负载时将成为瓶颈; -
TLB Shutdown
每当页面被替换时候,内核需要 flush TLB 来更新映射缓存,在多核场景下将触发 TLB Shutdown,这是一个很昂贵(数千个 cycles)的操作;
启示
业界关于 DBMS 要不要使用 MMAP 并非只有一种声音,这里还有 RavenDB 创始人的 re-are-you-sure-you-want-to-use-mmap-in-your-database-management-system 可供参考。我们还可以参考 codedump 老师的博客 mmap 适用于存储引擎吗?。
目前主流观点还是倾向于不用(或只用) MMAP 来实现数据库的 Buffer Pool。个人感觉还是挺符合第一性原理的:如果你想要有足够强的控制力来设计数据库,你就不能把关键的事情完全交给内核来做。一旦交给内核,数据库的瓶颈就和内核的实现强耦合。为了解决这类瓶颈,开发者就不得不针对内核的特性设计新的解决方案,当复杂度到达一定程度时,其实还不如自己来实现相应的机制更为划算。