CaaS-LSM 的设计 | 读读论文
Contents
论文地址
今天阅读是 SIGMOD 2024 的一篇 Paper,名为:CaaS-LSM: Compaction-as-a-Service for LSM-based Key-Value Stores in Storage Disaggregated Infrastructure 。
想解决什么问题
众所周知,基于 LSM 的 DBMS,Compaction 总是一个绕不开的话题,同时也是一个非常影响性能的关键因素:一旦对应系统发生 Compaction 这类重 IO 重 CPU 的操作,系统内的读写负载很多时候将受到影响,从而影响整体性能。
本论文是基于存算分离的 LSM KV 存储来设计 CaaS(Compaction-as-a-Service),试图将 Compaction 从 LSM-KVS 中解耦成一个无状态的服务,从而获得更高的吞吐和更低更稳定的 P99 延迟。这篇论文的亮点主要在于:
- 对 Remote Compaction 场景抽象了 Control Plane 和 Execution Plane,从而使整体架构更灵活;
- 提出了一些更有价值的调度策略,比如基于优先级的调度、基于 Local 和 Remote Compaction 的混合调度等;
- 更细致的 Error Handling;
设计
CaaS
整体设计如下:
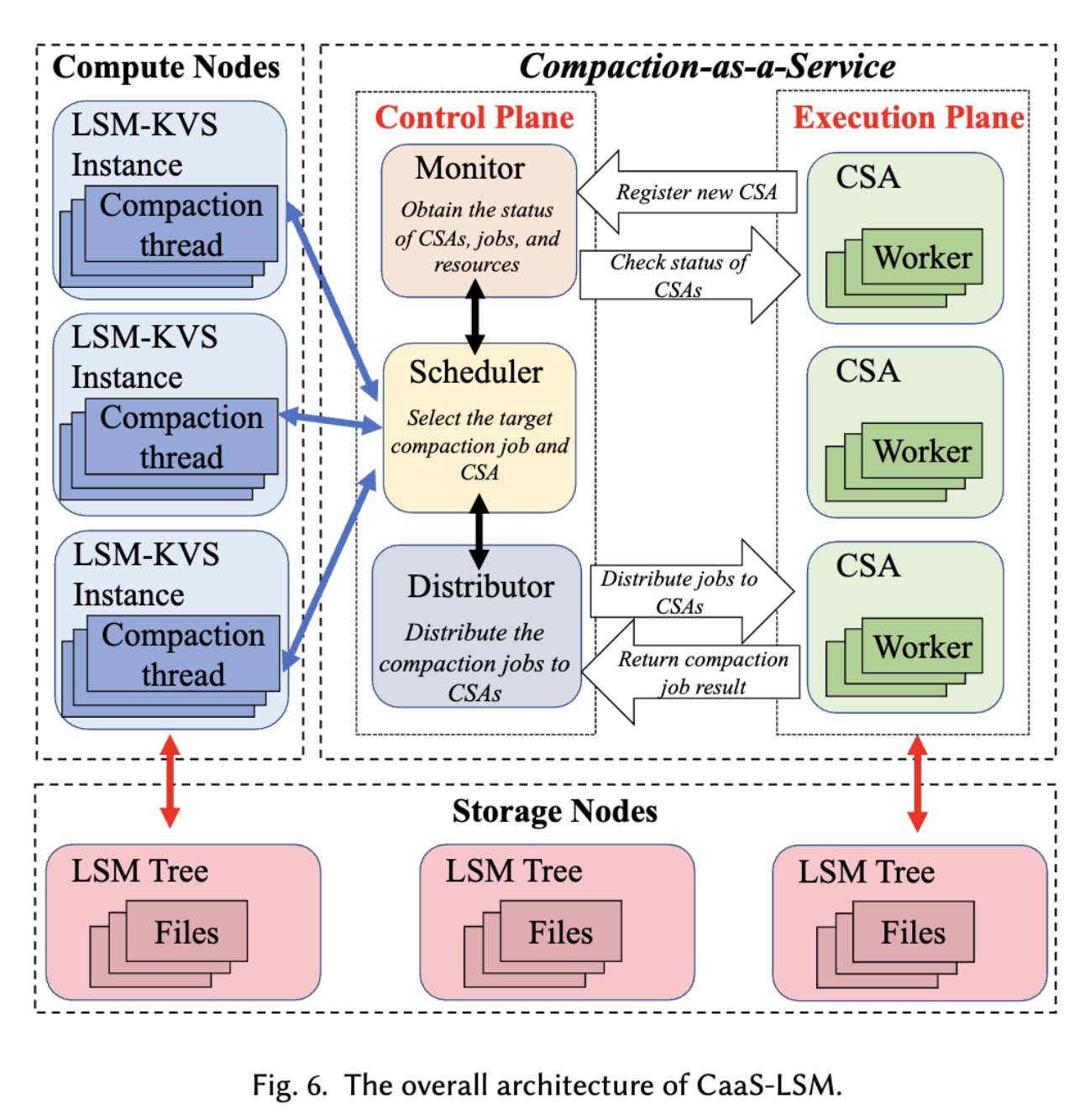
其中涉及这么几个组件:
-
Compute Nodes(或者叫 LSM-KVS):即计算节点;
-
Storage Nodes:具体的底层存储节点。如果是采用对象存储的系统,这里可以是 S3 这类对象存储;
-
Scheduler:当 LSM-KVS 触发 Compaction 时,会将对应的请求发送给 Scheduler,由 Scheduler 来将请求调度到对应的节点上(CSA)进行执行;
-
Distributor:当 Scheduler 将任务调度完成后,Distributor 则来分发具体的任务到 CSA 上(个人感觉 Distributor 有点冗余,可以将对应功能实现在 Scheduler 内部来简化整体设计);
-
Monitor:监控组件,用于监控 Job 、CSA 或者主机的状态,收集数据以做调度的决策;
-
CSA:即 Compaction Service Agents 的缩写。对应 Node 上将运行一个 CSA 的 Daemon 进程,用以真正执行 Compaction 任务。一个 CSA 节点将运行多个 Compaction 线程,可按需进行扩容。单个 Compaction 任务将被在一个线程内运行;
除了则几种组件,CaaS 还特别区分了 Control Plane 和 Execution Plane,即:
- Control Plane:Scheduler + Distributor + Monitor;
- Execution Plane:CSA;
交互流程
Control Plane 和 Execution Plane 的交互如下:
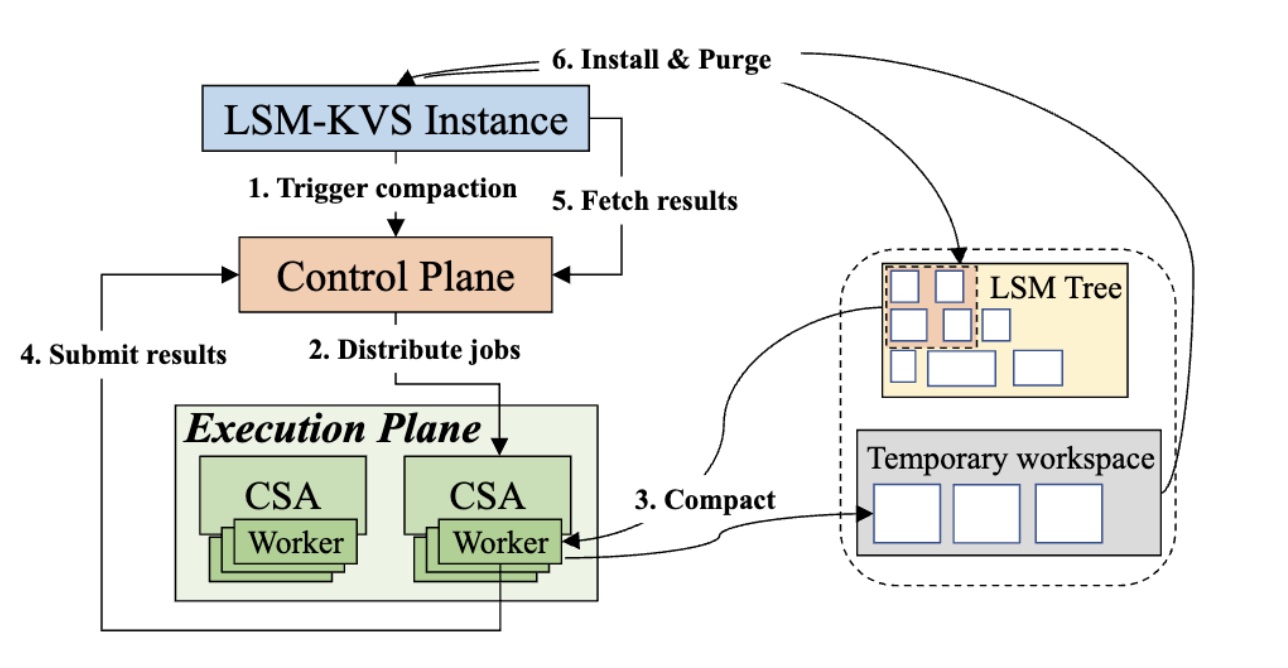
-
LSM-KVS Instance 触发 Compaction,并将 Compaction 请求发送给对应的 Control Plane,同时启动定时的轮询任务(比如 500ms)来检查 Job 的状态;
-
Control Plane 收到 Compaction 任务后,根据一定的调度算法来决定 Compaction 任务是否需要远端执行、执行的优先级以及具体要被调度到哪一个 CSA 上。如果所有 CSA 都处于繁忙状态,Control Plane 可以将 Compaction 退回到本地执行;
-
一旦 CSA 接收到了 Compaction 任务,它将启动相应的 thread 来执行这个请求:从 Storage Nodes 上读取目标 SST files 并执行 Compaction,生成的新的 SST files 将被存放在一个临时的 workspace 中;
-
CSA 执行完 Compaction 之后,会将对应的结果发送回 Control Plane;
-
此时 LSM-KVS Instance 也将通过轮询获得结果,会对 Compaction 的结果(比如 SST files)启动 double check;
-
LSM-KVS Instance 更新 Manifest(即元数据);
由于 CaaS 是以 RocksDB 为原型进行设计,我们同样可以参考 RocksDB 的 Remote Compaction
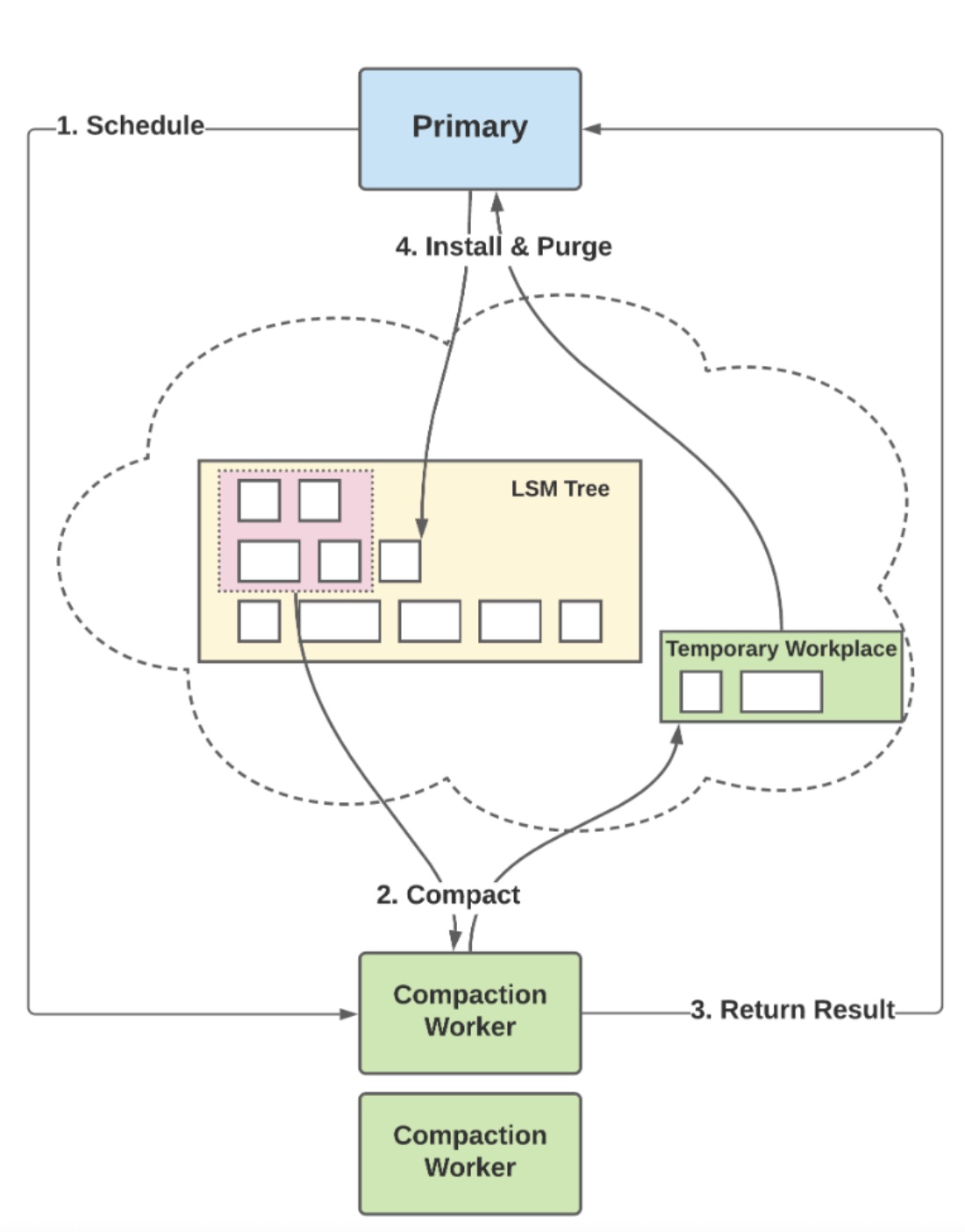
细节
Execution Plane
-
一个 CSA 在一个 Node 控制多个 Worker,每一个 Worker 都独占一个 Thread。Compaction 请求都由对应 Worker 执行。对于不同的 Compaction Job,CSA 可以分配不同的硬件资源,比如通过调节内存和 IO 带宽等来精确控制 Compaction 的执行速度;
-
CSA 将周期性收集必要的状态信息(比如 Compaction 的执行状态、资源利用率等)并返回给 Control Plane 和 LSM-KVS Instance 以供资源使用;
-
为了实现 Compaction 的无状态执行,CaaS 在 LSM-KVS 的 Compaction 准备阶段需要引入两组信息:
ControlMetadata:承载 LSM-KVS 提供 Compaction 的元数据信息,包括:input/output file level, location, size, priority 等等;CompactionServiceInput:执行 Compaction 的元数据信息,比如使用什么算法等;
-
LSM-KVS Instance 只需要添加两个接口:
CompactionService::Start:创建 Compaction 任务;WaitForComplete:等待 Compaction 任务完成;
Control Plane
-
Monitor 将 CSA 启动定期的心跳检查,以收集状态和资源信息。当 Job 分发到某个 CSA 或者 CSA 返回结果时,Monitor 也会更新该 CSA 最新的状态;
-
调度策略
-
基于 Priority 调度
当有多个 Compaction Jobs 时,Scheduler 将会为其进行排队,并通过请求中的
ControlMeta来为 Compaction Jobs 定义 Priority。将进行如下比较:- 手动 Compaction 比 Background Compaction 具有更高优先级;
- 比较输入的 SST file level:L0 > L1 > L3;
- Picker 可以提供一个 Score 值(RocksDB);
- 允许用户自行添加其他影响 compaction 优先级的元数据信息;
- Priority 的大小将决定了 Compaction Job 的执行顺序(如果没有 Priority 最简单则是用 FIFO)。
-
基于预估资源调度
通过请求中的
ControlMetadata中 SST file 文件大小信息来估算 compaction 所需的资源。然后基于以下方式来选择 CSA(实际上,这个调度算法可以根据具体场景进行调整):- 先剔除 CPU 和 Memory 已经超过 80% 的 CSA;
- 从已有的 CSA 候选列表中选择最充裕资源的 CSA;
- 如果资源还是不够,继续排队等待或者本地执行;
-
混合调度
因为 Remote Compaction 不是银弹,不一定所有的 Compaction 需要都走 Remote,如果 Local 的资源比较充足或者在 Local 运行比在 Remote 运行更有性价比,我们其实可以将 Compaction 放在 Local。Scheduler 可以根据一些策略来进行混合调度。比如可以在
ControlMetadata中增加如下元数据:- 最近几次 Compaction 在滑动窗口内历史执行时间(Local 和 Remote 都算);
- LSM-KVS 的 thread pool 利用率;
然后使用如下来计算估算的 Compaction 时间:

当计算了一个估算时间后,我们可以:
- 当 local thread pool 利用率已经很高了,使用 remote compaction;
- 当收到 CSA 资源不够的时候,执行 local compaction;
- 当预估的 local compaction 时间比 remote compaction 时间小时,执行 local compaction;
-
Fault Tolerance 和 Error Handling
论文将错误分成 3 种 level:
-
Job-level failure:比如 IO 错误、网络等问题导致 Job 执行失败,此时又可以再细分为:
- retriable error:比如 IO 错误、网络错误等。此时 control plane 会自动在同一个 CSA 上重试;
- solvable error:比如资源不够或者连接超时等,此时 control plane 会自动将 Job 调度到另一个 CSA 上;
- unrecoverable error:比如 data corruption 或者没有权限等,此时 control plane 会将直接将错误返回对应的 LSM-KVS instance;
-
CSA-level failure:一般是因为 CSA 崩溃、主机崩溃等原因导致,此时将失去与 CSA 的 heartbeat。此时 control plane 首先会尝试 reconnect CSA。如果 CSA 在多次重试无法恢复,control plane 会将 CSA 从注册列表中移除并将所有 compaction jobs 以最高优先级重调度到健康的 CSA 上;
-
Service-level failure:这意味着 control plane 无法正常响应 LSM-KVS 实例的请求。此时 LSM-KVS 会在本地执行 Compaction。
启示
没有免费的午餐
存算分离场景下的 Local Compaction 最大的问题就是资源竞争(CPU 和 IO 资源的竞争),而 Remote Compaction 本质上是资源的隔离和调度,从而在某种程度解决竞争,但随之也会带来其他成本,比如将提升系统复杂性和运维成本,在某些场景下也许还不如进一步改进 Local Compaction 算法或者调优其他参数 ROI 会更高。因此 Remote Compaction 并非万能的解法,得因地制宜。
我们该如何设计产品
Remote Compaction 与 Cloud 结合其实会非常有价值:
-
Remote Compaction 通过卸载了计算节点上的 Compaction 操作从而获得更高的性能,因此计算节点可以不必为 Compaction 预留太多资源;
-
Compactor 服务可以在云上按需扩缩从而避免资源的闲置和浪费。对于大规格的 Compaction,我们甚至可以运行在 Spot 节点上;
-
不仅仅是 Remote Compaction,其他一些资源密集型的操作在存算分离的场景都可以被卸载到远端,这篇论文的基础设计同样可以适配这类需求;
工业界目前做 Remote Compaction 暂时还不多,比如 Rockset 公司(刚被 OpenAI 收购)的这篇文章经常被提及。Rockset 提了一个 Compute-Compute Separation 的概念,其实大体上有点像读写分离、Remote Compaction 和 Remote Index。Rockset 会自动给每个字段加上索引,这种暴力美学不由得让人觉得他们应该是用了 Remot Index 。