OPA 开源项目介绍
Contents
什么是 OPA
OPA(发音为 “oh-pa”)是一个全场景通用的轻量策略引擎(Policy Engine),其核心项目托管于 OPA。OPA 提供了声明式表达的 Rego 语言来描述策略,并将策略的决策 offload 到 OPA,从而将策略的决策过程从策略的执行中接耦(OPA decouples policy decision-making from policy enforcement)。OPA 可适用于多种场景,比如 Kubernetes、Terraform、Envoy 等等。简而言之,以前需要使用到 Policy 的场景理论上都可以用 OPA 来做一层抽象,如下所示:
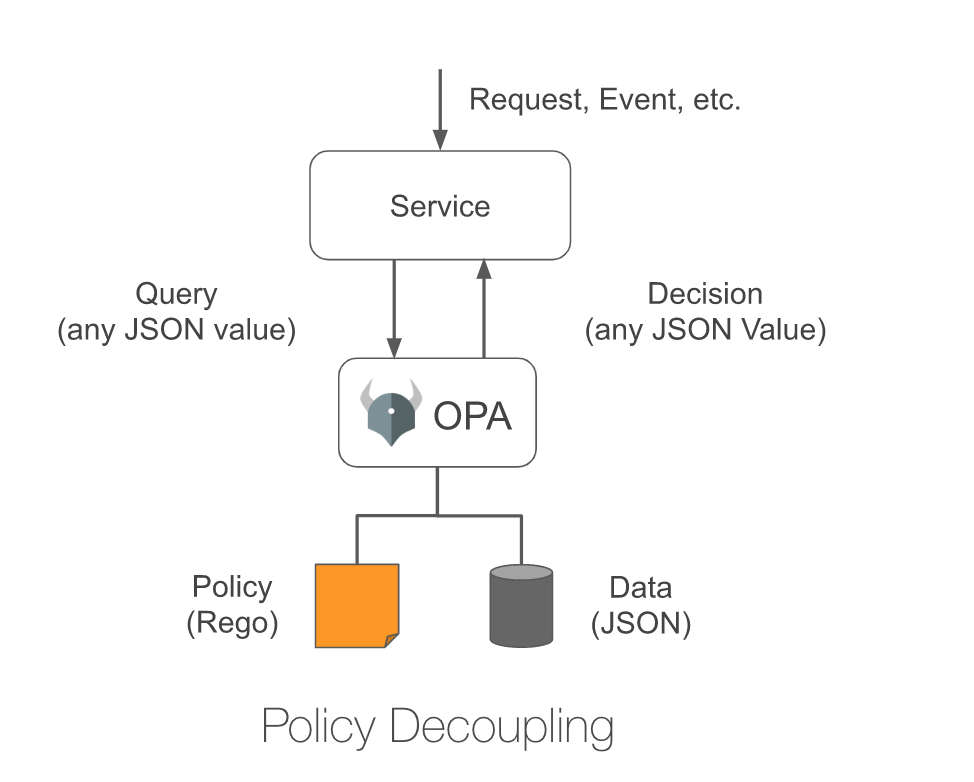
在大多数场景下,Policy 即是一系列用来控制服务的规则(可理解为就是 if-else 语句)。比如:
-
Authorization 场景
定义哪些用户(Identity)可对哪些资源(Resource)进行什么类型的操作(Operation)的规则;
-
网络防火墙规则
比如 iptables 中设定的规则,Kubernetes 中的 Network Policy 都可认为是与网络相关的 Policy;
-
资源准入控制
符合某种 Policy 的资源(比如必须设置某些属性或字段)才可以被业务层处理,否则将被拒绝服务,典型的有 Kubernetes 的 Admission Control 机制;
很多时候,Policy 的实现都与具体的服务耦合在一起,这导致 Policy 很难被单独抽象描述和灵活变更(比如动态加载新的规则)。而且,不同的服务对 Policy 有着不同的描述,比如采用 JSON、YAML 或其他 DSL,这样很难进一步将 Policy 以代码的形式进行管理(Policy As Code)。因此,为了更灵活和一致的架构,我们必须将 Policy 的决策过程从具体的服务接耦出去,这也是 OPA 整体架构的核心理念。如上图所示,在 OPA 的方案下我们对 Policy 的执行可抽象成以下 3 个步骤:
- 用 Rego 语言描述具体的 Policy;
- 当某个服务需要执行 Policy 时将这个动作(Query)交给 OPA 来完成(OPA 可以以 library 或者第三方服务的形式出现);
- OPA 在具体的输入数据下(Data)执行步骤 1 中的 Rego 代码,并将 Policy 执行后的结果返回给原始服务;
当采用 OPA 后,原来的服务架构可以简化为如下图所示:

OPA 的出现本质上还是为 Policy 相关逻辑增加一个抽象层。这样一来我们可以用统一的 DSL 和处理流程来完成 Policy 相关的逻辑,从而达到一致的架构设计。
Rego 语言的设计
Rego 语言为 OPA 项目提供一种领域无关的描述策略的声明式 DSL。Rego 的主要设计源于 Datalog(而 Datalog 又可以追溯到 Prolog,其实这些语言本质上都是为了求解一个逻辑问题),但是与 Datalog 不同的是,Rego 扩展了对 JSON 的支持。在 Rego 语言中,输入输出都是标准的 JSON 数据。
Rego 语言中最核心的一个功能的是对 Policy 的描述,即 Rules。Rules 是一个 if-then 的 logic statement。Rego 的 Rules 分为两类:complete rules 和 incremental rules。
complete rules 只会产生一个单独的值(即 true 或者 false):
|
|
每一个 rule 都由 head 和 body 组成,比如上文 any_public_networks = true 就是 head,剩下的 {...} 则为 body。
incremental rules 则将产生所有满足 body 的 value 的集合,比如:
|
|
当执行 public_network 时,将返回一个 set,比如:
|
|
当 rule 内部出现多个布尔判断时,它们之间是逻辑与的关系,即多个布尔表达式的逻辑与构成整个 rule 最终的结果。
当多个 rule 组合在一起,其表达的是逻辑或的关系:
|
|
则 shell_accessible 是寻找 servers 中支持 telnet 或 ssh 的变量。
使用 Rego 语言编写 Policy 其实就是编写一系列的 Rules。
除此之外,Rego 还支持一系列内置函数来简化日常使用,还可以采用单元测试的方式来输入测试数据从而验证 Rules 的正确性。
OPA 的应用
集成 OPA
OPA 的运行依赖于 Rego 运行环境,因此 OPA 提供了两种主要的使用方式:
-
Go Library
直接将 Rego 的运行环境以库的形式整合到用户服务中。当服务需要执行 Rego 代码时,只需要调用相关的 API 即可;
-
REST API
如果服务不是以用 Go 编写,为了拥有 Rego 运行环境,此时则必须使用 REST API。OPA 提供了一个 HTTP 服务,当其他组件需要执行 Rego 代码时,则将代码和数据一起以 REST API 的形式传给 OPA HTTP 服务,待 Rego 执行完后将相应的结果返回;
Kubernetes 中使用 OPA
Kubernetes 中使用 OPA 需要使用 Kubernetes Admission Control。拿最新发布的 Gatekeeper 项目为例,其主要的架构如下图所示:
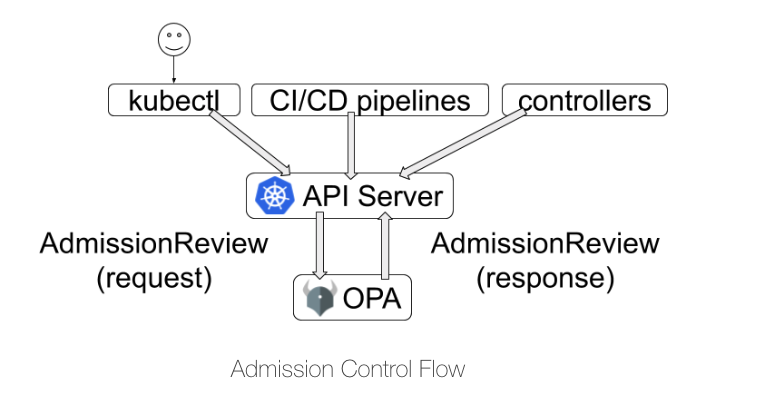
Gatekeeper 在 Kubernetes 中以 Pod 形式启动,启动后将向 API Server 中注册 Dynamic Admission Control,本质上就是让 Gatekeeper 作为一个 Webhook Server。当用户使用 kubectl 或者其他方式向 API Server 发出对资源的 CURD 请求时,其请求经过 Authentication 和 Authorization 后,将发送给 Admission Controller,并最终以 AdmissionReview 请求的形式发送给 Gatekeeper。Gatekeeper 根据对应服务的 Policy(以 CRD 形式配置)对这个请求进行决策,并以 AdmissionReview 的响应返回给 API Server。
Gatekeeper v3.0 的架构(2.0 版本是由 Microsoft Azure 团队开发并 donate 给了 OPA 社区)可如下所示:
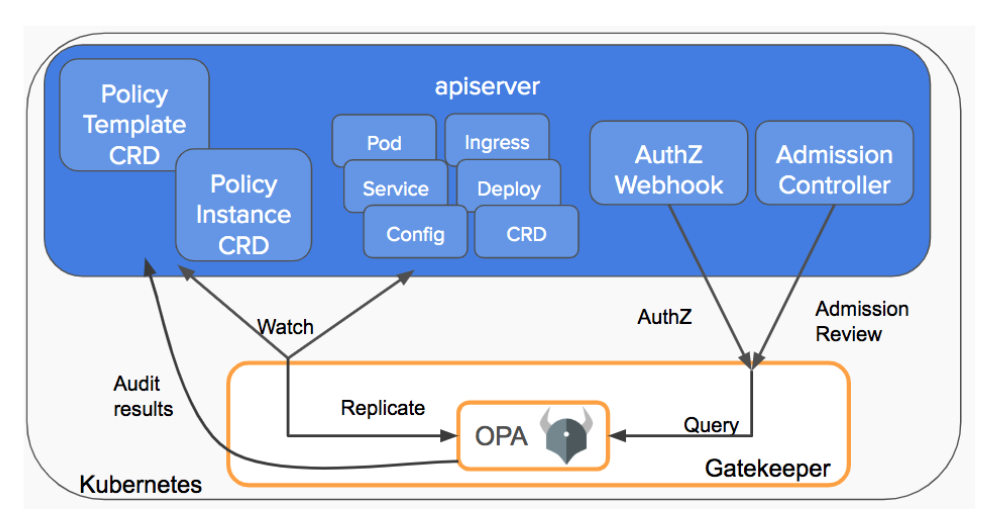
在目前的设计中,Gatekeeper 有 4 类 CRD:
-
ConstraintTemplate
ConstraintTemplate 和 Constraint 可认为是类似于类和实例的关系。ConstraintTemplate 的
rego字段用 Rego 语言具体描述了 Policy,但并没有指定 Policy 中具体的参数。ConstraintTemplate 也描述了生成 Constraint CRD 的 schema; -
Constraint
Constraint 可认为是对某一个 ConstraintTemplate 的实例化,其中对 ConstraintTemplate 的未指定参数进行了具体的配置。因此,对同一个 ConstraintTemplate 不同的参数配置可以生成多个 Constraint。Constraint 是由 ConstraintTemplate 这个 CRD 的描述再次由 Gatekeeper 生成的 CRD(即通过 CRD 再生成 CRD);
-
Audit
Gatekeeper 的 Audit 功能可以定期对从 Kubernetes 集群复制对应的资源应用具体的 Contraint,从而发现当前已存在服务中是否有违反 Policy 的配置。Audit 即是用以控制和配置该功能的 CRD;
-
Sync
Audit 功能在 Gatekeeper 执行 Policy 时需要从 Kubernetes 集群中复制(replication)资源,Sync 即是用来控制和配置这一过程的 CRD;
目前 Gatekeeper 仅支持 Validating Webhook,Mutating Webhook 正在开发中。
Gatekeeper 采用了 Kubebuilder 和 OPA Frameworks,其中 Contraint 相关的逻辑由 Frameworks 实现,所以核心逻辑并不复杂。
Gatekeeper 可认为获得了 Kubernetes 场景下一个可编程的 Webhook,通过输入不同的 DSL 就可获得不同 Validating 能力的 Webhook。毕竟,在 K8s 里头写一个 Validating 的 Webhook 是一个相当无趣且重复的工作,用一个统一的 Webhook 框架将让事情简单非常多。
OPA 的生态
OPA 的开发历史
OPA 是由 Styra 公司于 2016 年左右发起并主导开发,目前是 CNCF 孵化项目,仍处于开发阶段(最新版本号为 0.19)。
Styra 公司的产品就是基于 OPA 为 Kubernetes 提供 Policy 平台,从而让 Kubernetes 实现更细粒度的 Authorization,提升安全性。
从 2019 年来看,个人感觉 Policy 方面受到越来越多的关注。从 Microsoft Azure 团队和 OPA 团队主导开发 Gatekeeper 可看出,OPA 项目似乎越来越受到重视。比如在社区对 PodSecurityPolicy 的讨论中,就有人觉得原来 PodSecurityPolicy 的设计不够灵活且 API 不一致,且有人提议用 OPA 来替换这部分逻辑,但是因 Gatekeeper 仍不够稳定而暂时搁置。
目前社区以 OPA 和 Gatekeeper 这两个项目活跃程度最高。 Gatekeeper 的进度可通过查看会议纪要了解,看起来已经快到 GA 阶段。
Kubernetes 中的 Policy Working Group
Kubernets 中有着各种各样的 Policy:RBAC、Network Policy、Pod Security Policy、Scheduler Policy、ImagePull Policy 等等,为此,Kubernetes 社区成立 Policy Working Group 来跟踪改进和 Kuberntes 相关的 Policy 提议。OPA 的最核心作者 Torin Sandall 为其中的 Organizer 之一。
看了这个 Group 最近几个月的会议记录,目前有几个正在进行的项目:
- Guardian 项目:形式化验证云原生项目(比如 Kubernetes 的 RBAC)的框架,目前仍处于 PoC 阶段。感觉这个项目上手难度不小(涉及到形式化逻辑相关的知识),目前也没太多人参与;
- Container Policy Interface:类似于 CRI、CSI 等,为 Kubernetes 制定 Policy 相关的接口;
- 与 OPA 项目相关项目的讨论
等等。
OPA 存在的问题
OPA 的开销
OPA 的开销简单可分为两方面:Policy 执行性能开销和引入 OPA 层可能带来的网络开销。
Policy 执行性能开销即 OPA 执行 Rego 规则所带来的开销。从官方的数据来看,OPA 是一个高性能低延迟系统,其 Policy 的执行将控制在 1 毫秒以内。且即使随着 Policy 的增加,其开销也是近似常数时间。但是,跟大多数系统一样,如果没有按照 best practice 编写 Rego 规则同样会给 OPA 带来不正常的开销。但是从官方给出的描述上看,OPA 在大多数场景下其开销都是可被接受的。
OPA 还引入了不少对执行规则优化算法,其中比较重要的有:
- Rule Indexing:可将对规则执行从 O(n) 的遍历转换成一个 Tire 树查找,从而大大降低算法复杂度;
- Partial Evaluation:将 Policy 和对应的数据一起结合编译展开成符合 Rule Indexing 形式的 Rego 代码。这在特定的 Policy Data 下有很好的性能表现。但实际测试下,对于复杂规则,Partial Evaluation 编译出来的结果非常古怪,个人感觉这个算法还存在不少 Bug;
如果 OPA 不是作为一个库引入,而是整体作为一个 Web 服务引入(比如 OPA REST API、Kubernetes Admission Control 等),对某种资源的操作都需要经过 OPA 执行 Policy 后才进入下一步。除去 Policy 的执行成本,其主要开销即是网络层带来的多一跳。在 Kubernetes 的场景中,这个开销其实不算大(就算没有 OPA 的 Admission Control,还有其他各种原生的 Admission Controllers),跟资源 CURD 过程的其他环节比起来,这部分不是性能热点。但是在其他业务场景中,这需要具体问题具体分析。
Rego 语言的学习曲线
个人觉得,OPA 项目中最难的环节即是对 Rego 语言的学习。此处的难主要是与其他一些描述 Policy 的 DSL 做比较,比如被广泛使用的 JSON 或 YAML 这类配置型语言。Rego 语言与传统的编程语言有一定的差异(比如对 Rule 的描述),从语法的学习到能够熟练运用 Rego 写出符合 OPA 最佳实践的 Policy ,还是具备一定的学习曲线。虽然 Rego 语言为 OPA 带来统一且强大的 DSL,但同样也为 OPA 的落地增加了难度。
Rego 语言的设计来自于 Datalog,用声明式的方式去表达规则,没有显式的循环语句,整体风格比较类似于函数式编程,这对大部分熟悉命令式编程的用户提高了入门门槛。
业务改造成本
一般来说,系统已存在的 Policy 想换成 OPA 架构,是很难做到业务不侵入。无论如何,当前业务代码都必须进行相应程度的改造才能适用于 OPA。比如:
- 在自身项目中集成 OPA;
- 将原来的 Policy 抽象用 Rego 来描述;
类似的项目
社区中除了 OPA 之后,还有一些类似的与 Policy 相关的项目,比如:
-
Kyverno 是和 OPA 很像的项目,也是一个 Policy Engine,但是与 OPA 不同的是,Kyverno 采用 YAML 或 JSON 来描述 Policy。目前仍处于不稳定开发阶段,从 star 上看并没有受到太大的关注;
-
Sentinel 是由 HashiCorp(开发 Terraform 的公司)开发的一个内嵌形式的 Policy As Code 的框架。Sentinel 同样定义了用来描述 Policy 的 Sentinel Language(感觉和 OPA 使用的 Rego 语言还是挺类似的)。从官方的描述来看,Sentinel 的使用过程类似于以库的形式集成以使用 Policy Engine。可惜这不是一个开源产品,很难看到更多的细节;
-
与其他用 DSL 方式不同的是,Pulumi 走的是原生编程语言+SDK 的方式。这种做法可以让用户没有 DSL 的学习成本,直接使用主流编程语言来进行 Policy 领域的编程;
业界实践
备注:我在 2019 年 9 月左右的时候在互联网上找了不少资料,发现真正将 OPA 运用于生产环境的用户(除了 Styra 公司)还是及其稀少的,找了半天发现只有 Netflix 的工程师在 2017 年的 CloudNativeCon 上出来分享使用 OPA 的经验(后面发现 Azure 用 Gatekeeper 启动了一些服务)。所以 OPA 的稳定性和可靠性还需要更多的案例去证明,目前还很难说方案已经完全成熟。不过经过后面大半年的宣传和发展,近期的几个 KubeCon 都能看到将 OPA 应用于生产环境的案例,所以感觉 OPA 正在被越来越多的开发者接受和使用。
Netflix 采用 OPA 解决 Authorization 问题
通过视频(PPT)可以了解到,Netflix 的工程师想解决这么一个问题:
Netflix 内部有着相当多不同种类的微服务,服务之间有相互调用的需求,需要寻找一个较好的方式去解决服务间相互调用的 AuthZ 问题(即某一个服务可以以什么样的权限去调用另一个服务)。
Netflix 的工程师将 AuthZ 问题抽象为:
Identity can/cannot perform Operation on Resource.
即寻找一种简单统一的方式去管理 I、O 和 R 三要素,其中在 Netflix 中,Identity 类型可以是 VM/Container 服务、某个员工等等;Resource 类型不仅仅是 REST Endpoints,也包括 gRPC Method、SSH、Kafka Topics 等等。各种服务也没有统一的技术栈,每个服务可自由选择合适的编程语言,比如有 Java、Node.JS、Python、Ruby 等。
Netflix 的公司文化崇尚自由(Freedom)和负责(Responsiblity),每一个开发者需要对应用的整个生命周期负责(开发、测试、上线等等),所以开发者必须有自己定义 Policy 的自由,由开发者来决定一个服务具体可被谁使用。
Netflix 最终设计了如下架构:
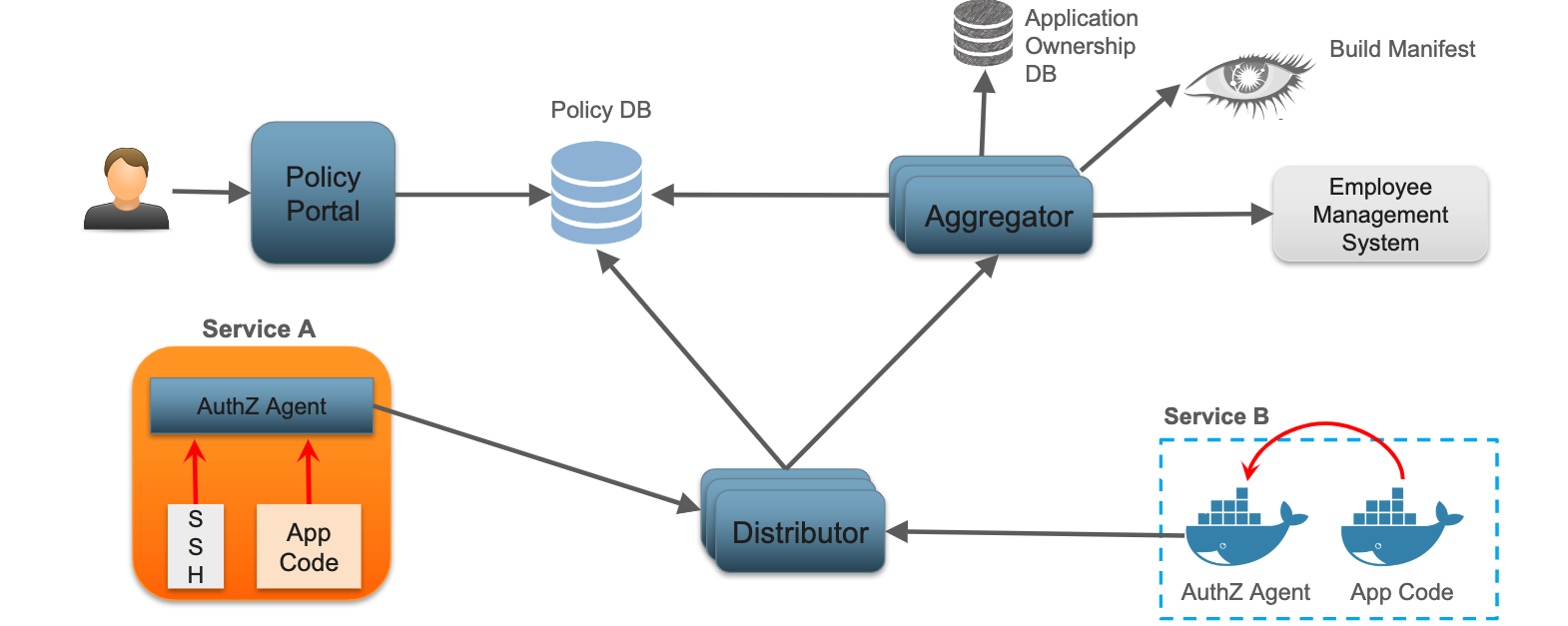
- 上层用户(通常是开发者)通过 Policy Portal 定义 Policy。Policy Portal 是一个 Web UI,帮助用户设置具体的 Policy,并最终将 Policy 持久化到 Policy DB;
- Aggregator 从多个渠道(比如 Application Ownership DB、Build Manifest、用户管理系统等等)聚合 Policy 到 Policy DB。也就是说,除了用户主动输入 Policy 外,系统也会从其他地方加载其他的 Policy;
- Distributor 从 Policy DB 和 Aggregator 拉取 Policy 并在内存中维护(Keep it hot),从而可以保证 Service 可以尽快访问 Policy。Distributor 采用可扩展设计,Service 的 AuthZ Agent 通过 Distributor 来拉取 Policy ;
- 每个 Service 都内嵌一个 AuthZ Agent(可能是以 sidecar 的形式部署,视频中似乎没有细说,但是可明确的是访问这个 Agent 不需要额外的网络访问),通过调用 AuthZ Agent 来实现 Policy decision;
而每一个 AuthZ Agent 的设计如下所示:
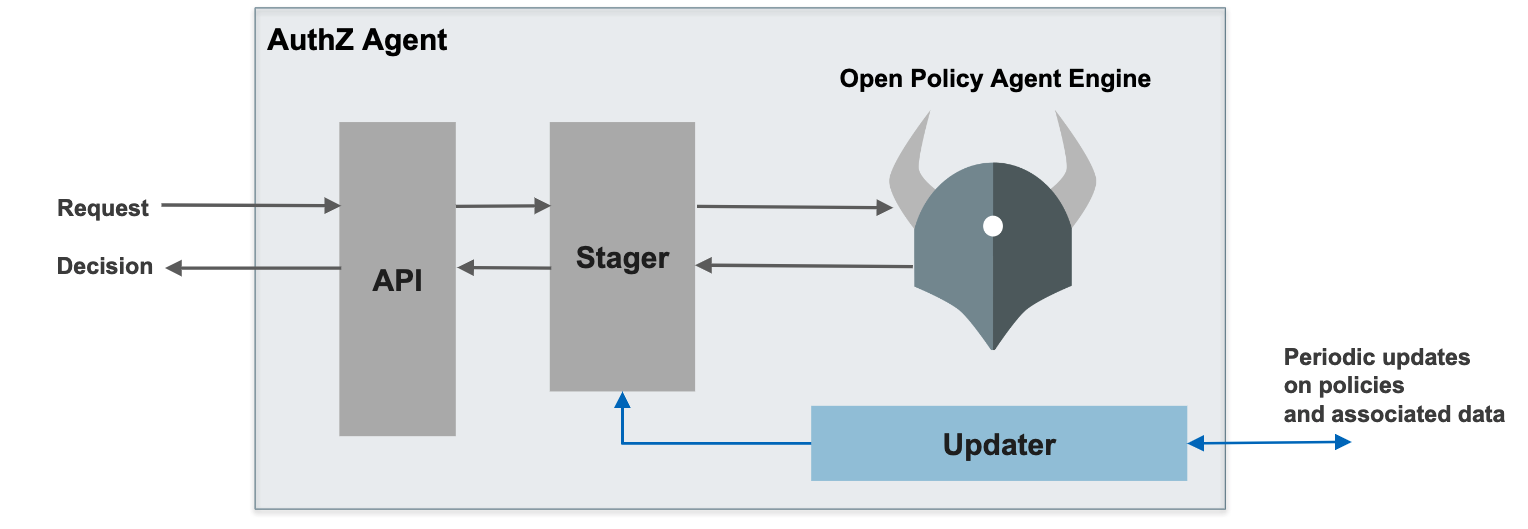
API 层提供 OpenAPI 来供上层业务调用,Stager 承接 API 和 OPA,将具体的请求和 Policy 进行转换并传给 OPA 做具体的策略执行。Updater 则是定期从 Distributor 中更新数据到 Stager 中。
Microsoft Azure 使用 Gatekeeper 作为 Policy 控制
Azure 团队(主要是 Rita Zhang)作为 Gatekeeper 的主要开发者,将 Gatekeeper 应用到了 AKS。在 Slack 上和 Rita Zhang 简单咨询了一下,目前这个服务只是 private priview 阶段(使用 Gatekeeper v2,后期会切换到 v3 版本),暂时应该还没有推广。
对 WebAssembly 的支持
OPA 在 v0.15.1 的时候支持了对 WebAssembly(下称 WASM)的支持。OPA 对 WASM 的支持可如下架构所示:
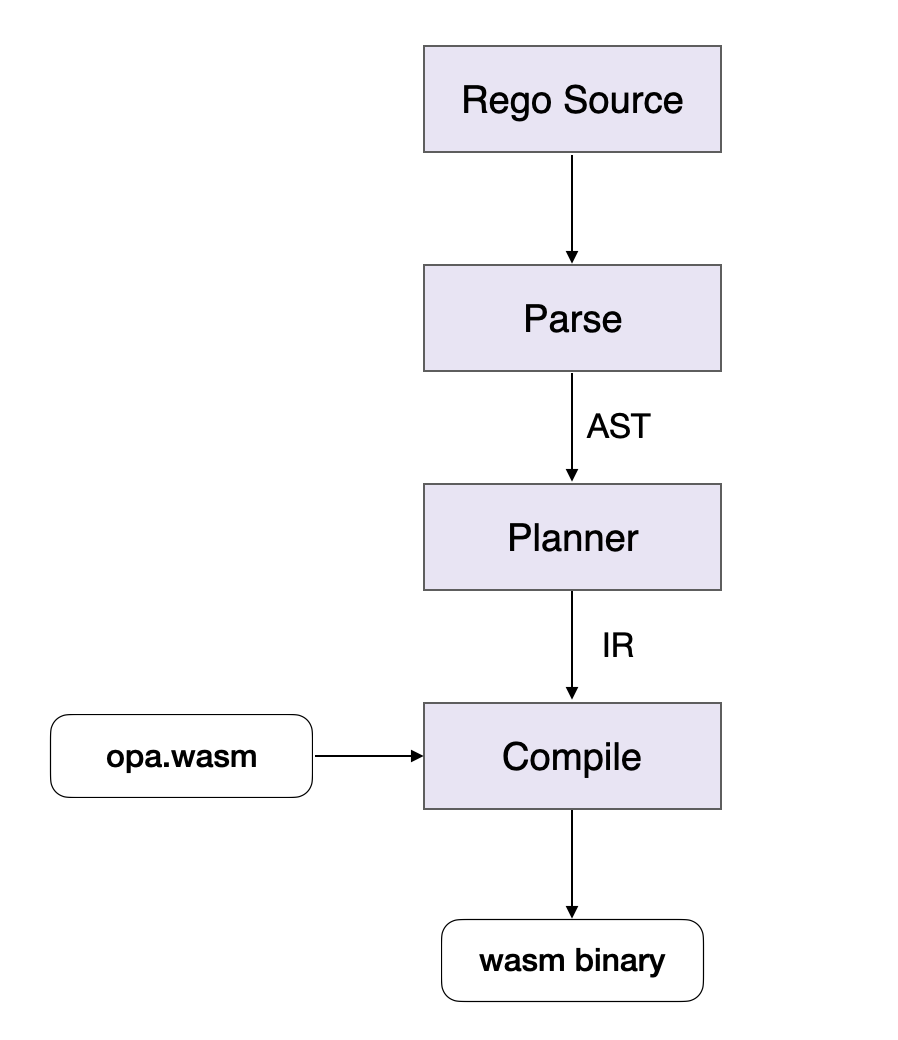
-
Planner 将 Rego 的 AST 转换成命令式的中间代码 IR;
-
Compile 环节将 IR 翻译成 wasm bytecode,其中 IR 使用到的底层函数都由
opa.wasm提供; -
opa.wasm是由 C 语言写的一系列不依赖于任何第三方库的运行环境,主要是:- JSON 的序列化和反序列化;
- 将 JSON 的对象转换成 OPA 的内置对象;
- 操作对象的函数(Insert、Compare、Get 等);
在 Compile 阶段,IR 所用到的外部函数都由
opa.wasm提供。比如 Rego 代码中的涉及到相关的比较最终都将转换成opa.wasm的某个 compare 函数。
WASM 作为目前最为通用的字节码标准,进一步提升了 OPA 的跨平台特性:只要用 Rego 语句写的 Policy,经过编译之后就能够任何 WASM runtime 上运行。而且从性能上看,编译成 WASM byetcode 执行性能要远远比用 Go 解释器执行的性能要高非常多。
但是 OPA WASM 目前同样还有不少坑:planner 生成的 IR 并非紧凑高效;很多内置函数到了 OPA WASM 上就没有实现;无法用上 Go 解释器对规则的优化算法等等。
其中也可以将 OPA Go 解释器编译变成一个 WASM 程序,从而输入依然是 Rego 代码而无须进行编译,也能充分利用起 Go 解释器的所有逻辑。但是这种做法的复杂度要比直接将 Rego 代码编译成 WASM 的复杂度要高很多,比如:
- 直接将 Go 代码编译成 WASM 并非完全成熟,Go 的 GC 是否能无缝切换为 WASM ?
- 涉及到很多对操作系统接口的使用当前 WASM 也还未完全支持和统一(比如 WASI 标准);
总而言之,将 Rego 编译成 WASM 是一件更为 Pratical 的事情且收益更大。我还是非常看好 WASM 未来的发展的前景,也许在未来,编程语言不可以主动编译成 WASM 将变成一件奇怪的事情。
Policy As Code 带来的价值
OPA 提出的 Policy Engine 的图景是很美好的,即 Policy As Code。如果能够将 Policy 以一种清晰统一的代码形式管理,那么可以我们至少可以获得以下几个好处:
-
全局统一的 Policy 描述方式
所有开发者对 Policy 的描述不再仅仅内嵌于业务代码中,也不再以多种不同的形式描述,而是以一种统一的语言进行表达;
-
提升运维效率
虽然应用 Policy As Code 初期可能会带来一定的学习成本,但是后期的价值是可以让 Policy 拥有类似代码的特性:
- 不同的 Policy 代码可以根据需求进行整合,比如每个业务必须先集成公司层面的 Policy 代码才可以开发自身业务相关的 Policy;
- 将安全准入的规则抽象成 Policy 代码供业务直接使用,从而让业务无需过多关注安全;
- 不同的 Policy 可以像代码一样进行自动化检查和测试(比如公司或组织层面的合规检查等);
- 更方便 Review;
-
提升业务架构灵活度
类似于 OPA 的接耦架构可让原来业务实现更为灵活的功能,比如:
- 动态更新和加载新的 Policy;
- 多个组件共享同一份 Policy 执行相关逻辑(比如多个组件共享同一个 Authorization 组件);
- 可编程能力:实现新的 Policy 只需要写新的 Policy DSL 即可,无须改变业务和框架层逻辑,理论上编写 DSL 代码的复杂度要远远小于用原生语言开发;
-
更细粒度和高效的安全保障
代码化后的 Policy 可以进行细粒度和灵活的描述,比如可以针对特定字段进行特殊判断等。针对 Authorization,可很容易根据这一特点实现黑白名单功能,这比以往使用 RBAC 形式的授权要更为灵活。
对安全的理解可抽象成 Policy 代码强制自动执行,这样对安全的保障不再仅仅依靠开发者自身意识或运维人员的配置 Review,而是直接以统一的代码形式体现;
总而言之,个人认为所谓 Policy As Code(或者 Infrastructure As Code、Security As Code 等等)本质上都是让原来对 Policy 描述抽象成代码,从而拥有代码的特性(复用性、抽象性、可执行、可测试、版本化等),以此来获得更高层次的抽象。但是,具体业务是否真正需要 Policy As Code,这种解耦是否真的有价值,还需要进行深入的思考。