什么是线性一致性读
关于什么是线性一致性读(lineariable read),其实已经有不少博客阐述得非常清晰,本文也不再赘述。这里可以推荐 TiDB 的一篇博客,讲得深入浅出,很适合入门。
所谓线性一致性读,可以简单理解为:当存储系统已将写操作提交成功,那此时读出的数据应是最新的数据(假设这期间没有新的写操作),CAP 理论中的 C(consistency)即是线性一致性。
由于在 Raft 算法中,写操作成功仅仅意味着日志达成了一致(已经落盘),而并不能确保当前状态机也已经 apply 了日志。状态机 apply 日志的行为在大多数 Raft 算法的实现中都是异步的,所以此时读取状态机并不能准确反应数据的状态,很可能会读到过期数据。
基于以上这个原因,要想实现线性一致性读,一个较为简单通用的策略就是:每次读操作的时候记录此时集群的 commited index,当状态机的 apply index 大于或等于 commited index 时才读取数据并返回。由于此时状态机已经把读请求发起时的已提交日志进行了 apply 动作,所以此时状态机的状态就可以反应读请求发起时的状态,符合线性一致性读的要求。这便是 ReadIndex 算法。
不过,我们在叙述的过程中忽略了一个很重要的点:如何准确获取集群的 commited index ?如果获取到的 committed index 不准确,那么以不准确的 committed index 为基准的 ReadIndex 算法将可能拿到过期数据。
为了确保 committed index 的准确,我们需要:
这样,我们从 leader 获取到的 commited index 就作为此次读请求的 ReadIndex。
确保 Leader 的有效性
让我们来设想一个网络分区的场景:
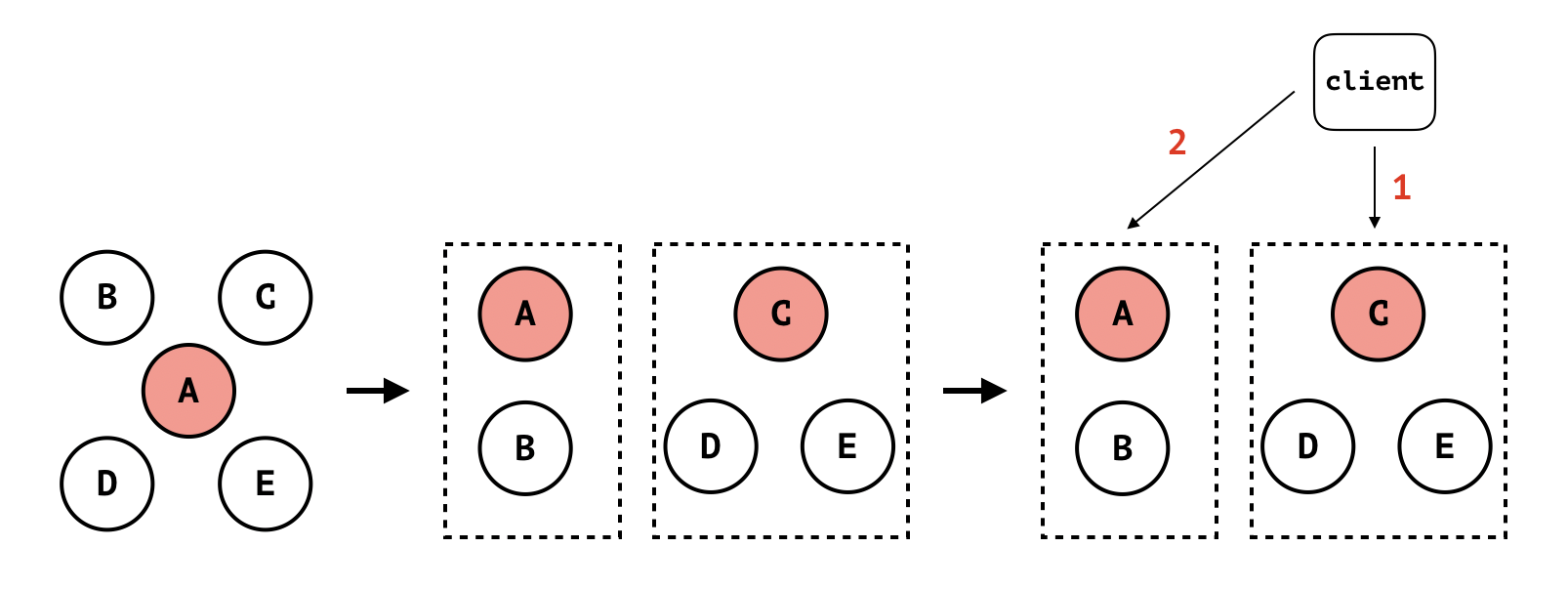
如上图所示:
- 初始状态时集群有 5 个节点:A、B、C、D 和 E,其中 A 是 leader;
- 发生网络隔离,集群被分割成两部分,一个 A 和 B,另外一个是 C、D 和 E。虽然 A 会持续向其他几个节点发送 heartbeat,但由于网络隔离,C、D 和 E 将无法接收到 A 的 heartbeat。默认地,A 不处理向 follower 节点发送 heartbeat 失败(此处为网络超时)的情况(协议没有明确说明 heartbeat 是一个必须收到 follower ack 的双向过程);
- C、D 和 E 组成的分区在经过一定时间没有收到 leader 的 heartbeat 后,触发 election timeout,此时 C 成为 leader。此时,原来的 5 节点集群因网络分区分割成两个集群:小集群 A 和 B,A 为 leader;大集群 C、D 和 E,C 为 leader;
- 此时有客户端进行读写操作。在 Raft 算法中,客户端无法感知集群的 leader 变化(更无法感知服务端有网络隔离的事件发生)。客户端在向集群发起读写请求时,一般是从集群的节点中随机挑选一个进行访问。如果客户端一开始选择 C 节点,并成功写入数据(C 节点集群已经 commit 操作日志),然后因客户端某些原因(比如断线重连),选择节点 A 进行读操作。由于 A 并不知道另外 3 个节点已经组成当前集群的大多数并写入了新的数据,所以节点 A 无法返回准确的数据。此时客户端将读到过期数据。不过相应地,如果此时客户端向节点 A 发起写操作,那么写操作将失败,因为 A 因网络隔离无法收到大多数节点的写入响应;
针对上述情况,其实节点 C、D 和 E 组成的新集群才是当前 5 节点集群中的大多数,读写操作应该发生在这个集群中而不是原来的小集群(节点 A 和 B)。如果此时节点 A 能感知它已经不再是集群的 leader,那么节点 A 将不再处理读写请求。于是,我们可以在 leader 处理读请求时,发起一次 check quorum 环节:leader 向集群的所有节点发起广播,如果还能收到大多数节点的响应,处理读请求。当 leader 还能收到集群大多数节点的响应,说明 leader 还是当前集群的有效 leader,拥有当前集群完整的数据。否则,读请求失败,将迫使客户端重新选择新的节点进行读写操作。
这样一来,Raft 算法就可以保障 CAP 中的 C 和 P,但无法保障 A:网络分区时并不是所有节点都可响应请求,少数节点的分区将无法进行服务,从而不符合 Availability。因此,Raft 算法是 CP 类型的一致性算法。
etcd 如何实现线性一致性读
按照 etcd 如何用 bbolt 存储数据 这篇文章的方法,我们还是用基于情景的方式来分析 etcd 如何实现线性一致性读。
情景:利用 etcd 的客户端发起读请求时,服务端如何响应读请求 ?
客户端读请求的发起过程
etcd v3 版本中采用的是 gRPC,所以此时客户端和服务端都是通过 gRPC 进行交互。
在 etcd/clientv3 中,客户端的读请求即是一个 Get 请求:
1
2
3
4
5
6
|
// etcd/clientv3/kv.go
func (kv *kv) Get(ctx context.Context, key string, opts ...OpOption) (*GetResponse, error) {
// 所有的客户端操作都将转换为 kv.Do()
r, err := kv.Do(ctx, OpGet(key, opts...))
return r.get, toErr(ctx, err)
}
|
OpGet() 将 Get 请求转换为一个与 gRPC 相关的结构体:
1
2
3
4
5
6
|
// etcd/clientv3/op.go
func OpGet(key string, opts ...OpOption) Op {
ret := Op{t: tRange, key: []byte(key)}
ret.applyOpts(opts)
return ret
}
|
我们才看一下 kv.Do() 的实际处理函数 kv.do():
1
2
3
4
5
6
7
8
9
10
11
|
func (kv *kv) do(ctx context.Context, op Op) (OpResponse, error) {
...
switch op.t {
case tRange:
var resp *pb.RangeResponse
// 即 Get 请求本质上是一个 gRPC 的 Range 请求
resp, err = kv.remote.Range(ctx, op.toRangeRequest(), grpc.FailFast(false))
...
}
...
}
|
由此可以看出 Get 请求其实就是一个 gRPC 的 Range RPC:
1
2
3
4
5
6
7
8
9
10
11
|
// etcd/etcdserver/etcdserverpb/rpc.proto
service KV {
// Range gets the keys in the range from the key-value store.
rpc Range(RangeRequest) returns (RangeResponse) {
option (google.api.http) = {
post: "/v3alpha/kv/range"
body: "*"
};
}
...
}
|
服务端的处理过程
客户端发起一个 Range RPC,我们只需要看服务端如何实现 Range RPC 即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// etcd/etcdserver/v3_server.go
func (s *EtcdServer) Range(ctx context.Context, r *pb.RangeRequest) (*pb.RangeResponse, error) {
...
// 如果需要线性一致性读,执行 linearizableReadNotify
// 此处将会一直阻塞直到 apply index >= read index
if !r.Serializable {
err := s.linearizableReadNotify(ctx)
if err != nil {
return nil, err
}
}
// 执行到这里说明读请求的 apply index >= read index
// 可以安全地读 bbolt 进行 read 操作
var resp *pb.RangeResponse
var err error
chk := func(ai *auth.AuthInfo) error {
return s.authStore.IsRangePermitted(ai, r.Key, r.RangeEnd)
}
get := func() { resp, err = s.applyV3Base.Range(noTxn, r) }
if serr := s.doSerialize(ctx, chk, get); serr != nil {
return nil, serr
}
return resp, err
}
|
由此可见 Range() RPC 的核心在于 linearizableReadNotify():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// etcd/etcdserver/v3_server.go
func (s *EtcdServer) linearizableReadNotify(ctx context.Context) error {
// 获取 readNotifier,本质上就是一个 channel
// 当可以安全进行读请求是,将从这个 channel 得到信号(notifiy)
s.readMu.RLock()
nc := s.readNotifier
s.readMu.RUnlock()
select {
// 如果可以顺利发送成功,说明 read loop 协程已经准备处理此次读请求
case s.readwaitc <- struct{}{}:
// 默认跳过去
default:
}
// 等待可以线性一致性读的信号
select {
// 接收到信号,说明 apply index 已经大于或等于 read index,可以返回,结束等待状态
case <-nc.c:
return nc.err
case <-ctx.Done():
return ctx.Err()
case <-s.done:
return ErrStopped
}
}
|
从这段函数可以看出 linearizableReadNotify() 的逻辑是:
-
获取 readNotifier;
-
等待读请求处理协程可以处理此次读请求 ;
-
等待 readNotifier 的通知,即 apply index 大于或等于 read index;
因此处理的核心便到了读请求处理协程,即 linearizableReadLoop()。
etcd 在启动的时候会启动 linearizableReadLoop() 对应的 goroutine:
1
2
3
4
5
6
|
// etcd/etcdserver/server.go
func (s *EtcdServer) Start() {
...
// 启动 linearizableReadLoop() goroutine 来处理只读请求
s.goAttach(s.linearizableReadLoop)
}
|
linearizableReadLoop() 顾名思义是一个 for-loop:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
func (s *EtcdServer) linearizableReadLoop() {
...
for {
// 这里的命名有点不好,此处的 ctx 其实是 request id
// 为每一个读请求赋予一个唯一的 id
ctx := make([]byte, 8)
binary.BigEndian.PutUint64(ctx, s.reqIDGen.Next())
// 如果能从 readwaitc 接收到信号则说明有新的读请求到来
// 否则将一直阻塞在 receive 环节
select {
case <-s.readwaitc:
case <-s.stopping:
return
}
// 创建一个新的 notifier 对象让其下一次读请求使用
nextnr := newNotifier()
s.readMu.Lock()
// 将当前的通知通道拷贝到 nr 并将其换成 nextnr
nr := s.readNotifier
s.readNotifier = nextnr
s.readMu.Unlock()
// 调用 raft 模块来获取当前读请求的 read index
cctx, cancel := context.WithTimeout(context.Background(), c.Cfg.ReqTimeout())
// ReadIndex() 对应的是从 raft 模块发出 read index 请求
if err := c.r.ReadIndex(cctx, ctx); err != nil {
...
}
...
// ReadIndex() 发出了 read index 请求
// 接下来就是处理 read index 请求的返回
// 如果成功返回将可以从对应 channel 接收到信号
var (
timeout bool // read index 请求是否超时
done bool // read index 请求是否完成
)
// 阻塞等待 read index 请求完成
// 请求完成说明当前读请求已经获取到对应准确的 read index
for !timeout && !done {
select {
// 如果接收到消息,说明 read index 请求完成
case rs = <-s.r.readStateC:
// 检查 request id 是否正确
done := bytes.Equal(r.RequestCtx, ctx)
...
}
}
// 如果有问题,放弃此次 loop
if !done {
continue
}
// 此处就是等待 apply index >= read index
if ai := s.getAppliedIndex(); ai < rs.Index {
select {
// 等待 apply index >= read index
case <-s.applyWait.Wait(rs.Index):
case <-s.stopping:
return
}
}
// 发出可以进行读取状态机的信号
nr.notify(nil)
}
}
|
综上,linearizableReadLoop() 逻辑就是:
- 等待是否有新的读请求到来,如果有,进行下一步处理;
- 调用 raft 模块发出 read index 请求;
- 等待 raft 模块处理完 read index 请求,当成功处理完后,此次读请求的 read index 已被获取;
- 等待 apply index 大于或等于 read index,当这个条件满足时,发出通知信号;
Raft 协议库对读请求的处理过程
由上可以看到,真正进行 read index 请求的过程在 raft 算法库中:
1
2
3
4
5
|
// etcd/raft/node.go
// 发出 read index 请求
func (n *node) ReadIndex(ctx context.Context, rctx []byte) error {
return n.step(ctx, pb.Message{Type: pb.MsgReadIndex, Entries: []pb.Entry{{Data: rctx}}})
}
|
follower 接收到 read index 请求
对于 follower 来说,当接收到 MsgReadIndex 时:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// etcd/raft/raft.go
func stepFollower(r *raft, m pb.Message) {
switch m.Type {
case pb.MsgReadIndex:
// 如果没有 leader,出错处理
if r.lead == None {
....
}
// 将消息的目标地址修改为集群的 leader,把读请求 forward 给 leader
m.To = r.lead
r.send(m)
...
}
}
|
leader 接收到 read index 请求
对于 leader 来说,当接收到 MsgReadIndex 时:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// etcd/raft/raft.go
func stepLeader(r *raft, m pb.Message) {
switch m.Type {
case pb.MsgReadIndex:
// 如果法定节点数量超过 1 个
// 这也是大多数执行路径
if r.quorum() > 1 {
...
switch r.readOnly.option {
// ReadOnlySafe 就是执行 read index 算法的逻辑
case ReadOnlySafe:
// 将请求添加到队列中
r.readOnly.addRequest(r.raftLog.commited, m)
// leader 节点向其他节点发起广播
r.brcastHeartbeatWithCtx(m.Entries[0].Data)
// ReadOnlyLeaseBased 是另外一种线性一致性读的算法,后续再说
case ReadOnlyLeaseBased:
....
}
} else {
....
}
}
}
|
逻辑并不复杂,就是先将请求保存在队列中,并向其他节点发起广播(check quorum)。
read_only.go 的处理逻辑
在 etcd/raft/read_only.go 中,提供了对只读请求的处理,其中定义了 readOnly 数据结构:
1
2
3
4
5
6
7
8
9
10
11
|
type readOnly struct {
// 采用哪一种线性一致性读算法
option ReadOnlyOption
// 待处理的读请求队列
// key 是 request id,value 是此次读请求的相关元数据
pendingReadIndex map[string]*readIndexStatus
// 读请求队列,以 request id 作为 value
readIndexQueue []string
}
|
当使用 addRequest() 的时候:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func (ro *readOnly) addRequest(index uint64, m pb.Message) {
// ctx 是 request id
ctx := string(m.Entries[0].Data)
// 如果已经在待处理请求队列中则直接返回
if _, ok := ro.pendingReadIndex[ctx]; ok {
return
}
// 将请求加到一个 hash 中:key: 第一个 entry 的内容;value: 构建一个 readIndexStatus
ro.pendingReadIndex[ctx] = &readIndexStatus{index: index, req: m, acks: make(map[uint64]struct{})}
// 将读请求的 request id 添加到 readIndexQueue 中
ro.readIndexQueue = append(ro.readIndexQueue, ctx)
}
|
此处要注意 readIndexStatus 数据结构:
1
2
3
4
5
6
7
8
9
10
|
type readIndexStatus struct {
// 读请求的消息体
req pb.Message
// 此次读请求的 commited index
index uint64
// 此次读请求发起 check quorum 收到的 ack
acks map[uint64]struct{}
}
|
我们看到当 leader 处理读请求,先是调用 addRequest() 添加读请求,接着就向其他节点广播心跳且 payload 是 request id,当 leader 收到心跳的响应时:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func stepLeader(r *raft, m pb.Message) {
switch m.Type {
...
case pb.MsgHeartbeatResp:
...
// 积累收到的 ack
ackCount := r.readOnly.recvAck(m)
// 如果还没收到法定节点数量的 ack 直接返回
if ackCount < r.quorum() {
return
}
// 收到足够多的 ack,清理队列的 map 和 queue 并将此时读状态添加到 readStates 队列中
// 上次会将 readStates 包装成 Ready 数据结构透给应用层
rss := r.readOnly.advance(m)
for _, rs := range rss {
req := rs.req
if req.From == None || req.From == r.id {
r.readStates = append(r.readStates, ReadState{Index: rs.index, RequestCtx: req.Entries[0].Data})
} else {
r.send(pb.Message{To: req.From, Type: pb.MsgReadIndexResp, Index: rs.index, Entries: req.Entries})
}
}
...
}
}
|
由此可见,当一次 read index 完成后,会将其对应的元数据组成 ReadState 数据结构添加到对应读状态队列中。 r.readStates 也是 Ready 数据结构的一部分。
raft 模块也有一个 for-loop 的 goroutine,这个 goroutine 将不断的创建 Ready 数据结构透给上层应用:
1
2
3
4
5
6
7
8
9
|
func (n *node) run(r *raft) {
...
for {
...
rd = newReady(r, prevSoftSt, prevHardSt)
...
}
...
}
|
而在 newReady() 中:
1
2
3
4
5
6
7
8
|
func newReady(r *raft, prevSoftSt *SoftState, prevHardSt pb.HardState) Ready {
...
// 将已完成 read index 的读请求队列传给 Ready 数据结构
if len(r.readStates) != 0 {
rd.ReadStates = r.readStates
}
return rd
}
|
而在应用层:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// etcd/etcdserver/raft.go
func (r *raftNode) start(rh *raftReadyHandler) {
...
go func() {
...
for {
...
case rd := <-r.Ready():
...
// 处理已完成 read index 请求的读
if len(rd.ReadStates) != 0 {
select {
// 每次只将最后一个 read state 发送给 r.readStateC
// 上文有提及监听 r.readStateC 直到收到对应的 read state 后才进行状态机的等待
case r.readStateC <- rd.ReadStates[len(rd.ReadStates)-1]:
....
}
}
}
...
}()
...
}
|
至此,一个完整的读请求完成 !
对 ReadIndex 算法的优化
从上面的层层分析可以看到,一次完整的只读请求是有好几个等待环节的:
其中耗时最大应该是 check quorum 环节,因为这带来了额外的网络交互。
此处 etcd 还实现了一种相对不安全但是性能较高的读算法:LeaseRead 算法。
关于 LeaseRead 算法的论述,开头提及的 TiDB 博客讲得很好,etcd 的实现也非常简单,此处也不一一叙述。
读 Go 源码的一点体会
由于 Go CSP 的模型,各个协程通过 channel 来进行彼此之间的同步,从而形式异步化的处理模型。说实话,这种模型比基于 Actor 的并发模型的直观程度要大打折扣。
在 Actor 模型中,消息的上下文是有明确的发送方和接收方的(每个协程都有自己的身份 ID 和 mailbox),然后在 Go 中,消息的接收方则是监听了 channel 的 goroutine。
所以,在看 Go 代码时,一旦看到有 channel 的时候,一定要借助工具(比如 IDE)来分析出对应的监听者,这样你才能明确知道消息流转的上下文:这边发出消息之后,谁来接收消息并进行下一步。
不小心又把文章写成有点冗长的源码分析,写作能力有待提升,祝大家读得愉快 !