AWS EC2 机型漫游小指南
Contents
背景
AWS EC2 是 AWS 的弹性计算服务,为广大开发者提供便捷弹性的虚拟机,是 AWS 历史最悠久的服务之一(另外一个是 S3),从 2006 年发布至今,已经发展了近 17 年历史。
相信不少刚开始接触 EC2 的朋友都有如下类似的感受:
- AWS EC2 的类型实在是太多了(数百种)!我究竟应该选择哪一种 EC2 机型既能满足业务需求且不超过预算 ?
- EC2 的 CPU 和 Memory 配置一样,是不是代表它们的性能差异也一样 ?
- 采用什么样的 EC2 付费模式才比较划算 ?
回想 EC2 刚开始发布时,只有两种机型可供选择,而如今则多达有 781 种,琳琅满目的 EC2 类型必然会让开发者们陷入选择困难症。由于 EC2 技术细节繁多,本文只能简单介绍一些 EC2 机型选择的小技巧,目的是为了帮助读者能更快地选择合适的 EC2 机型。文末稍微扯点题外话,做一些无关紧要的漫游,读者可随意阅读。
机型分类和选择
总体分类
尽管 AWS 有数百种 EC2 机型,但其实只有以下几种大的分类:
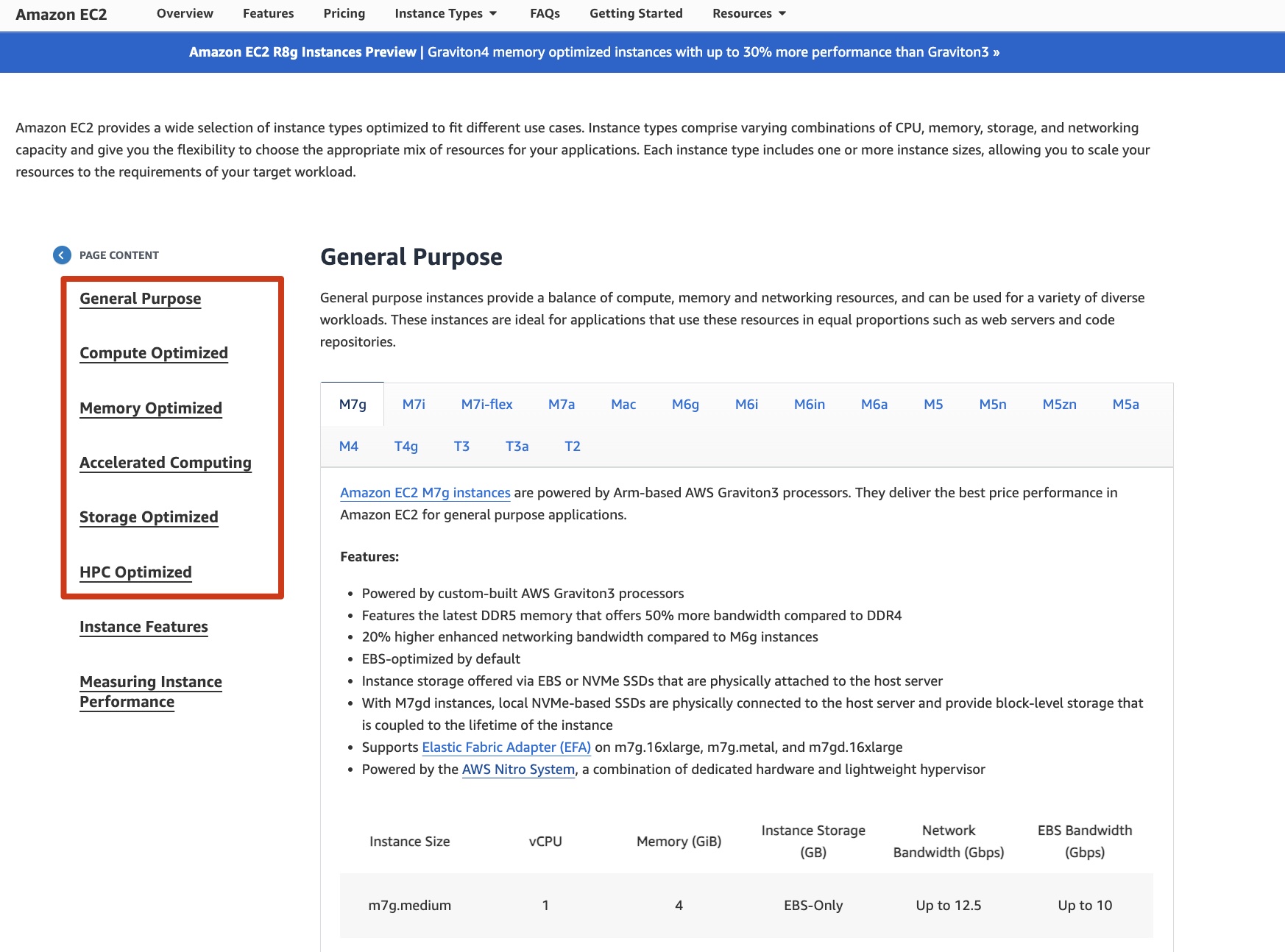
- General Purpose:Compute、Memory 和 Networking 资源相对平衡,即 M 系列和 T 系列。绝大多数场景用 General Purpose 就足够了;
- Compute Optimized:计算优化型,适合计算密集型服务,即 C 系列;
- Memory Optimized:内存优化实例旨在为处理大型数据集的工作负载提供快速性能,主要有 R 和 X 系列;
- Accelerated Computing:加速计算实例使用硬件加速器或协处理器来执行功能,例如浮点数计算、图形处理或数据模式匹配,比在 CPU 上运行的软件更高效;
- Storage Optimized:存储优化实例专为需要在本地存储上对非常大的数据集进行高速连续读写访问的工作负载而设计;
- HPC Optimized:这是 AWS 新出一个分类(HPC 系列),主要适用于需要高性能处理的应用程序,例如大型复杂模拟和深度学习工作负载;
一般来说,每一个具体的 EC2 型号都从属于某个带有相应数字序号的 Family,比如以 General Purpose 类型的 M 系列为例:
- M7g / M7i / M7i-flex / M7a
- M6g / M6i / M6in / M6a
- M5 / M5n / M5zn / M5a
- M4
从序号上我们不难看出,M7 是最新一代的产品,而 M4 则是相对比较旧款的型号。序号越大,则说明对应的机型和 CPU 型号也就是越新,同等配置下价格也有可能会更实惠(硬件总是在不断贬值)。
关键参数
从 AWS 一个典型的 EC2 型号介绍,我们可以提取出以下几个关键参数:

-
EC2 的具体型号
一般以
<family>.<size>命名,比如m7g.large/m7g.xlarge等。对于 EC2 来说,某种型号在全局是唯一的; -
CPU 和 Memory 大小
即上图中的
vCPU和Memory大小。绝大多数 EC2 机型都是 1:4,即 vCPU 和 Memory 的数量上的比值。比如,当 vCPU 为 1 时,Memory 通常是 4GiB;当 vCPU 为 2 时,Memory 通常是 8GiB,以此类推; -
实例存储
EC2 通常可以挂载不同类型的持久化存储盘,主要有以下几种:
-
EBS
挂载 AWS 的分布式块存储服务,这通常是大多数 EC2 机型默认选择。有些机型只能选择使用 EBS。EBS 是与具体 AZ 相绑定,读写延迟当然会比本地 SSD 要差一些,但在大多数场景下也能接受。根据 IOPS 和吞吐量等一些参数的不同,EBS 也有不同的类型,比如:
-
gp2/gp3:底层是通用型的 SSD,官方目前推荐使用性价比更好的 gp3。一般默认是 3000 IOPS,但是也支持无停机按需提升 IOPS;
-
io1/io2:更强的性能和更贵的价格,同时还支持 Multi Attach 这类特性(一般其他类型的 EBS 只能挂载一台 EC2);
-
-
本地存储
某些机型除了支持挂载 EBS 外,同时还支持本地存储,当然,价格上也会更贵一些。一般这类机型的型号上都会带有
d,比如:m7g.large是 EBS-Only 的机型,而m7gd.large则是带有 1 块 118GiB NVME SSD 本地存储的机型。某些特殊机型还支持容量更大本地 HDD;
-
-
EBS 带宽
对于一些比较新且有专门的 EBS 优化的 EC2 机型,AWS 都会为其配备专用的 EBS 带宽。这意味着在高数据量吞吐的场景,EBS 优化机型总能享有更好的吞吐而不与本机上的网络带宽有资源竞争;
-
网络带宽
即 EC2 机型对应的网络带宽。
-
CPU 型号
大多数场景下,我们能看到以下几种厂商的 CPU:
- AWS 自研的基于 ARM 架构的 Graviton 处理器(目前已经到 Graviton 3),比如
M7g系列; - Intel x86-64 架构的 CPU;
- AMD x86-64 架构的 CPU;
一般来说,相近配置上价格上是:Intel > AMD > Graviton,性能则刚好反过来。对于一些性能不敏感的通用化场景,用户可以考虑使用 ARM 架构的机型从而获得更高性价比。
AWS 是最早尝试将 ARM 架构引入服务器 CPU 领域的云厂商,经过多年的研发,Graviton CPU 已经取得长足的进步,性价比上有很大的竞争优势,估计未来 AWS 会推动越来越多的客户使用 Graviton CPU 机型。侧面也看出 Intel 在服务端的逐渐没落。
- AWS 自研的基于 ARM 架构的 Graviton 处理器(目前已经到 Graviton 3),比如
-
虚拟化技术
不同的 EC2 机型底层使用的虚拟化技术也是不完全相同的,这也导致了一些参数上的差异。比如对于较新的 EC2 机型,一般都采用 Nitro 虚拟化技术。Nitro 是 AWS 最新的虚拟化技术,将很多虚拟化行为都卸载到了硬件上,而软件上则可以做得相对较轻量,从而虚拟化性能会更强,从用户视角感受到则是相同配置下会有更好的性能(因为虚拟化的 Overhead 更低了)。
-
是否用于机器学习场景
随着 LLM 技术的发展,越来越多的厂商会选择在云端训练自己的模型(某种程度上也是因为 GPU 供应紧俏)。如果想在 AWS EC2 训练模型,一般会使用 Accelerated Computing 这个大类的机型,比如:
- P 系列和 G 系列机型:这部分使用的是 Nvidia 的 GPU 芯片。在 re:Invent 2023 大会上,Nvidia 与 AWS 开启了更深度的战略合作,AWS 计划使用 Nvidia 最新最强的 GPU 来打造一个专门用于生成式 AI 的算力平台;
- Trn 和 Inf 系列:AWS 除了使用 Nvidia GPU,自己也研发专用于机器学习的芯片,比如用于训练的 Trainium 芯片和模型推理的 Inferentia 芯片。Trn 系列和 Inf 系列的 EC2 机型则分别对应这两种 AWS 自研的机器学习芯片;
价格模式
On-Demand
这是默认的付费模式,基本就是按需使用,随时启停。每一种机型都会有一个小时费率(可通过 ec2instances 进行查阅),AWS 将根据你的使用时间进行收费(不足 1 个小时将按照 1 个小时进行收费)。 虽然这是最灵活的方式,但同样也是最贵的方式。
为了能相对更好地表达对应的价格,我以 AWS EC2 通用机型较新的几款机型为例,将小时费率折算成月度费率,简单绘制了下面这张图:
| large(2c8g) | xlarge(4c16g) | 2xlarge(8c32g) | 4xlarge(16c64g) | |
|---|---|---|---|---|
| m7g(arm) | 59.5680 | 119.1360 | 238.2720 | 476.5440 |
| m7i(intel) | 73.5840 | 147.1680 | 294.3360 | 588.6720 |
| m6g(arm) | 56.2100 | 112.4200 | 224.8400 | 449.6800 |
| m6i(intel) | 70.0800 | 140.1600 | 280.3200 | 560.6400 |
| m5(intel) | 70.0800 | 140.1600 | 280.3200 | 560.6400 |
| t4g(arm) | 30.7330 | 61.5390 | 123.0780 | N/A |
| t3(intel) | 60.7360 | 121.4720 | 242.9440 | N/A |
以 ARM 的 8c32g 机型为例,一年的使用费用就要 238.2720*12 = 2859.264 美金,相同价格其实可以购买到配置更高的服务器。On-Demand 最大的好处就是灵活,但如果灵活启停并非最主要需求时,可以先考虑换一种付费模式。
Saving Plans
Saving Plans 其实是:用户向 AWS 承诺未来对 EC2 的某个使用量,AWS 则给予用户一个更便宜的费率。举个例子,如下图 AWS 的 Saving Plans 的购买图为例:
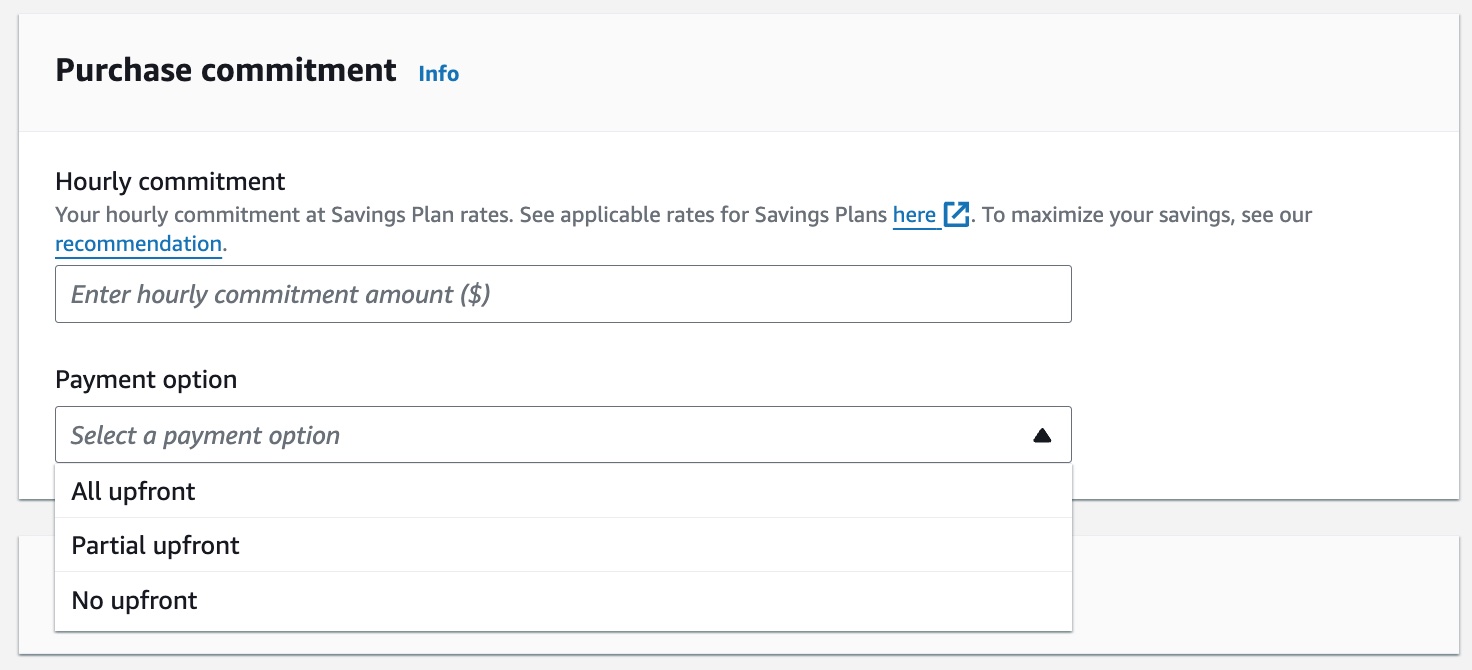
用户需要填写他们承诺每小时使用 EC2 的金额(为了简化,AWS 会有 Recommender 来根据你当前业务情况计算出一个推荐值)。根据付款方式的不同,有 All upfront(全预付)、Partial upfront(部分预付)和 No upfront(无预付)三种类型。当然,预付比例越高,优惠越多。一旦你购买了 Saving Plans,你的基础消费其实就固定了。即使你实际使用量低于承诺使用量,你也必须付给 AWS 承诺的费用。如果你的实际使用量高于承诺使用量,高出的那部分将以 On-Demand 进行额外计费。
Saving Plans 以年为单位(1 年或者 3 年),而且一旦购买就很难取消或者变更,相对适合业务资源比较稳定的场景。
Saving Plans 大体可分为:
- Compute Savings Plans :不限制机型区域,只要是计算实例(甚至是 ECS、Lambda 等),都可以使用;
- EC2 Instance Savings Plans:限制机型区域,无法灵活切换,但折扣相对会比 Compute Savings Plans 要低;
如果你不清楚使用哪一种,建议使用 Compute Saving Plans,这样灵活度会相对更高。
Reserved Instance
Reserved Instance(RI)与 Saving Plans 类似,但是限制更多(比如限制区域与机型),与此同时也带来了更低的费率。
Spot Instance
Spot Instance 是一个非常具有 Cloud 特点的产品。像 AWS 这种巨型的云厂商,每个区域的算力其实不太可能做到百分百卖出去。那些闲置的空余算力则被打包成 Spot Instance 以一种随市场波动的价格的方式进行售卖。同类机型下,Spot Instance 的费率会大幅低于 On-Demand 模式的费率,但也正由于其市场波动性,AWS 不会让用户有长时间占有某个 Spot Instance,而是有可能会被随时抢占。一旦 AWS 觉得对应实例有更划算的用户购买,则会将终止当前 Spot Instance(提前两分钟通知)。一般来说,Spot Instance 比较适合容错性较高的计算型服务。
Key Takeaways
根据我们上文的一些简单介绍,我们总结了一下小技巧供读者参考:
-
对于大多数 EC2 机型,一般序号越大,CPU 型号越新,性能会越强,价格反而会越便宜(或者相差无几),即性价比更高;
-
EC2 通用型中 T 系列相对便宜,并且提供了一种 Burstable CPU 的特性:实例在基线性能下运行会累积 CPU 积分,当遇到基线性能之上的高负载场景时可根据 CPU 积分运行超出基线性能一定时间的能力(费用不变),但随之也带来 T 系列性能不会太高,普遍带宽也低且没有 EBS 优化。因此 T 系列比较适合非性能验证的测试环境;
-
EC2 通用型系列中如果追求性价比,可优先选择 AWS ARM 架构;
-
AWS 官网的 EC2 Pricing 非常难以阅读,推荐使用 Vantage 的 ec2instances 来查阅价格信息(这也是一个开源项目);
-
对于大多数云用户来说,EC2 的费用一般是其大头支出,这里有几个手段可以尽量减低这方面的开支:
- 充分拥抱云的弹性,让你的架构尽可能弹性,按需使用算力,这里可使用 AWS 的 Karpenter 或者 Cluster Autoscaler 来让你的 EC2 具备灵活伸缩的能力;
- 使用 Spot 实例:可以提供比原始实例便宜 30% 甚至更多的实例,但是会被抢占。AWS 会在抢占前 2 分钟提醒你,然后就进行抢占。Spot 实例如果底层管理得好,非常适合弹性计算且可容忍中断的场景,比如 SkyPilot 项目就是拿不同的云的 Spot 实例进行机器学习训练;
- 优化付费模式:除了技术手段,我们其实还可以通过购买 Saving Plans 等方式来获得比 On-Demand 更低廉的单位使用时间,但缺点就是灵活度降低,比较适用于整体业务架构相对稳定的场景;
题外话
有趣的 ec2instances
当我在研究各种 EC2 类型的时候,我被 AWS 官方的价格表整得痛苦不已:不仅不直观而且还非常难用。这时候偶然发现了 Vantage 公司的 ec2instances,如获至宝。难能可贵的是,这还是一个开源项目 ec2instances.info。于是我兴奋地发了条 Tweet 表达了我对这个项目的喜爱并得到了一些推友们的评论:
btw,Eugene 是我们 GreptimeDB 的 Committer,他的评论提到了这个项目的历史。根据大家的评论,我很快知道了这个项目的原作者 Garret Heaton。ec2instances 原本只是 Garret 运营了 10 年之久的 side project,但之后被 Vantage 收购。最近一段时间经常关注 indie hacker 的故事,我感觉这个案例就是 indie hacker 非常不错的例子。从技术的角度分析,ec2instances 其实不是一个很难的项目,但确实是一个显著改善开发者体验的好产品。好的产品永远比好的技术更重要。
FinOps 与上云下云
在上文提到了 Vantage,我就顺便研究了下 FinOps。随着云作为基础设施不断渗透,云的用户其实迫切需要更清晰的 Cost Observability(比如最近进 CNCF Sandbox 的 OpenCost)并基于这类数据和云的特点来做更好的财务规划,因此有了 FinOps 这类更精细化的运维方向。国内外其实也诞生了不少做 Cost Management 的公司,说白了,就是让客户知道钱花到哪了以及如何省钱。知道钱花到哪其实不是特别难做,难的是如何让客户省钱,换个国内用户熟悉点词就是 “降本增效”。不同的客户都有不同的技术架构、使用场景和体量,脱离这些具体要素谈降本增效不一定准确。比如我们经常听说离在线业务混部可以显著降低成本,但前提是对应业务要有足够的规模和潮汐效应,以及投入研发混部的人力成本能显著低于收益。对于大部分普通公司,其实稍微做点软件性能提升和严格的支出管理,说不定就能立马降低费用。
就目前来看,大部分云厂商的显性成本显著高于原始硬件成本,因此也诞生下云的说法,其中以 37Signals 的 DHH 最为著名。通过下云,他们大幅降低了服务器成本,而且整体服务的质量还能维持不变。抛开这个相对激进的例子,绝大多数公司的主体软件还是继续朝云的方向演进。对于绝大多数公司而言,用云是相对更划算事情,云提供的便利性和可靠性短期内是很难靠自建基础设施获得的。构建一朵云绝对是一个极重资产的过程:
- 你必须有足够多的资金来采购硬件,而且你的采购量要足够大,以至于在供应链上有足够多的议价权,以此获得更具性价比的芯片和更优质的带宽线路等等;
- 你必须有足够多的专业人才来研发适用于云的基础软件,这部分人才培养成本高而且数量上并不多,人力成本也比普通的软件工程师高;
- 你必须有足够多的时间和用户来打磨产品,不断试错,积累运营经验,从而才有机会进一步优化架构;
因此,除非你自身体量足够大,否则构建云并不太划算。对于中等规模的公司,自建云并不总划算,相同质量下选择云并基于云的特点来设计软件架构则更为可取和稳妥。而且,随着云厂商自身的技术升级和资源的进一步集聚,云的费用可能会逐步降低,最终上云才是主流。传统的非云软件会逐渐没落,取而代之的是以云作为主要场景进行研发的各类软件。不仅如此,未来肯定也是一个多云的时代,但是多云下的会诞生什么样的产品形态,目前还是一个未知和探索的领域(个人比较喜欢 SkyComputing 这个概念)。